
Adapting Grammatical Error Correction Based on the Native Language of Writers with Neural Network Joint Models
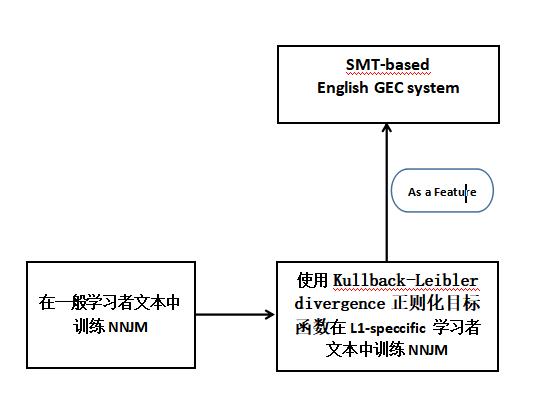
本篇论文: 采用一个使用L1-specific学习者文本的NNJM(神经网络联合模型),并把它作为一个feature整合到一个基于GEC的统计机器翻译系统(解码器)中。
本文的两点贡献:
- 这是第一个使用SMT方法并覆盖所有错误类型的工作来对GEC执行基于L1的自适应
- 我们引入了一种新的NNJM适应方法,并证明该方法可以处理比一般域数据小得多的域内数据。 适应(Adaptation)是通过使用训练在一般域数据上的未适应的NNJM来完成的。使用自归一化的对数似然目标函数作为起点,使用较小的L1-specific的域内数据进行后续迭代训练,并使用包含Kullback-Leibler (KL)离散正则项的修正目标函数。
摘要
尽管第一语言(The Native Language,L1)对第二语言(The Second Language,L2)的写作有显著的影响,但是基于作者母语(L1)的适应(Adaptation)是 语法纠错(GEC)任务仍未充分探索的一个重要方面。本文采用神经网络联合模型(神经网络联合模型,NNJM),使用L1-specific的学习者文本,将其集成到基于统计机器翻译(SMT)的GEC系统中。具体地说,我们针对一般学习者文本(general learner text,不是L1-specific的)训练NNJM,然后再使用Kullback-Leibler divergence正则化目标函数训练L1-specific的数据,以保持模型的泛化。我们将这个调整后的NNJM作为一个基于SMT的英语GEC系统的功能,并表明该系统在L1中文、俄语和西班牙语作者的英语文本上获得了显著的F0.5。
为什么考虑 L1-specific 学习者文本?
主要是L1背景不同,学习第二语言时有不同的影响,也就是L1和L2之间的跨语言影响。
芬兰的英语学习者:过度概括了介词‘in’的使用。
例如:“When they had escaped in the police car they sat under the tree.”这个句子中的介词"in" 应该为 “from” 。中国的英语学习者:由于汉语中没有动词形态变化,所以在书写英语时经常会出现动词时态和动词形式错误。
第一语言对第二语言写作的跨语言影响是一个非常复杂的现象,学习者所犯的错误不能直接归因于两种语言的相似或不同。
- 学习者似乎遵循着两个互补的原则(Ortega 2009):第一语言中起作用的可能在第二语言中起作用,因为人类语言基本上是相似的;但如果听起来太像L1,那么在L2中可能就行不通了。
- 因此本文采用数据驱动(data-driven)的方法对这些影响因素进行建模,并使用具有相同L1背景的作者撰写的L2文本对GEC系统进行调整。
Why SMT ?
GEC中两个最常用的方法是:分类方法(the classification approach)和 统计机器翻译方法(the statistical machine translation approach)。
SMT的优势:
SMT方法把不合语法的文本转换成格式良好的文本的学习文本转换的能力,使得它能够纠正各种各样的错误,包括复杂的错误,而这些错误是很难用分类方法(the classification approach)处理的,这也使得SMT成为GEC的流行范例。
SMT方法并不用于专门的错误类型建模,也不需要像解析(parsing)和词性标注(POS tagging)这样的语言分析。
NNJM –> Neural Network Joint Model
关于NNJM在论文Fast and Robust Neural Network Joint Models for Statistical Machine
Translation(Devlin et al.,2014)
NNJM:通过一个源上下文窗口扩展NNLM(which augments the NNJM with a source context window)。该模型是纯词汇化(purely lexicalized)的,可以集成到任何MT的Decoder中。具体来说,该模型利用m-word源窗口扩展一个n-gram目标语言模型。和以往的联合模型不同,该模型能够很容易作为一个feature被整合到任何SMT解码器中。

NNJM近似地估计了以源句子S为条件的目标假设T的概率。遵循目标的标准n-gram LM分解,其中每个目标字ti都受前面的n- 1个目标字的制约。为了使这个模型成为一个联合模型,对源上下文向量 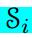 进行了条件分析:
进行了条件分析:
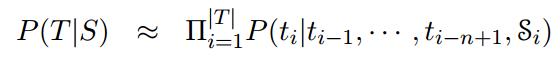
每一个目标词ti都直接对应着一个在位置ai的源词,是在以ai为中心的m-word的源窗口。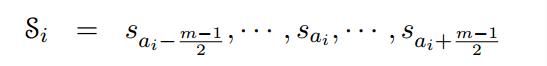
这种从属(affiliation)概念源自单词对齐,但与单词对齐不同,每个目标单词必须与一个非空(non-NULL)源单词相关联。

中文-英语平行句子的NNJM上下文模型例子如下图:

论文中采用的是n=4、m=11的15-gram LM 模型(神经网络语言模型能够优雅地扩展并利用任意大的上下文大小)。论文中的神经网络结构与Bengio et.al等人的前溃神经网络语言模型结构基本相似,如下图。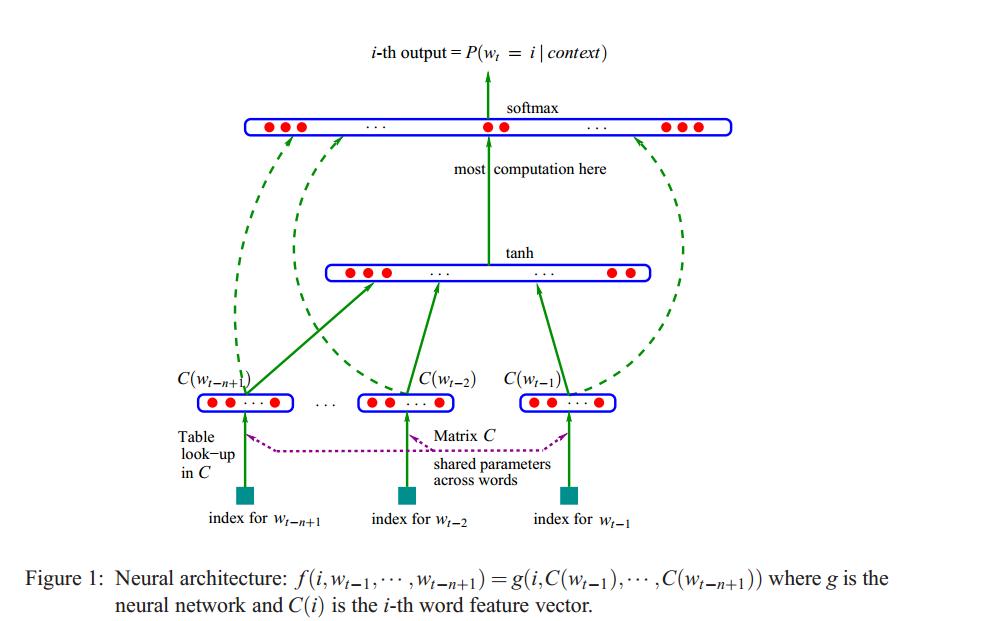
NNJM中的神经网络结构
NNJM中的神经网络架构与Bengio et al.(2003)所描述的原始前馈NNLM体系结构(feed-forward NNJM architecture)几乎相同。
隐藏层大小、词汇表大小和源窗口大小选择了这些值:

由于NNJM使用的是一个固定窗口的上下文,所以很容易将其整合到SMT解码器框架中,实验结果也证明了这样提升了SMT-based GEC的性能。
A MT Framework For GEC
本文中将GEC视为从一个可能错误的输入句子到一个纠正句子的翻译过程。
框架设计细节:
- 采用一个基于短语的SMT系统–Moses框架,它主要是通过一个对数线性模型来找到最佳假设 T*:

SMT中两个主要部分:翻译模型(TM)和语言模型(LM)。
- TM: 主要负责生成假设T(通常是短语表),使用并行数据(即,学习者写入的句子(源数据)及其相应的校正句子(目标数据))进行训练。还使用正向和反向短语翻译概率和词汇权重等特征对假设进行评分,从而选出最佳假设T*。
- LM: 在格式良好的文本上进行驯良从而保证输出的流畅性。用MERT计算特征权重
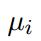 ,用开发集优化
,用开发集优化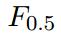 度量。
度量。
- 由于NNJM有依赖于固定上下文的前馈结构,所以很容易将其作为一个feature整合到SMT解码器框架中。特征值由logP(T|S)给出,这个logP(T|S)是给出上下文的假设T中每个单词的对数概率总和。

上下文hi由n-1个之前的目标词和围绕与目标词ti对齐的源词的m个源词组成。
- 神经网络输出层的每个维度(Chollampatt et al., 2016)给出了给定上下文h的输出词汇表中单词t出现的概率。

- 神经网络中的参数包括权值、偏差和嵌入矩阵都是用带随机梯度下降反向传播进行训练,损失函数使用的是与Devlin等所用(2014)相似的自归一项的对数似然目标函数。
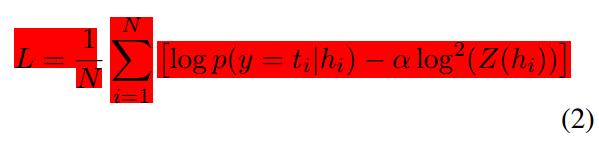

KL Divergence Regularized Adaptation

in-domain data: 由L1-specific的作者所写的错误文本及其相应的修正文本组成。
这种自适应训练是使用具有正则化项K的修正目标函数来完成的,该函数用于最小化pGD(y|h)与网络输出概率分布p(y|h)之间的KL离散度。 K将防止训练期间估计的概率分布偏离通用域NNJM的分布。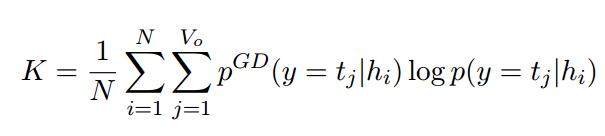
最终的自适应步骤的目标函数是L和K中的项的线性组合。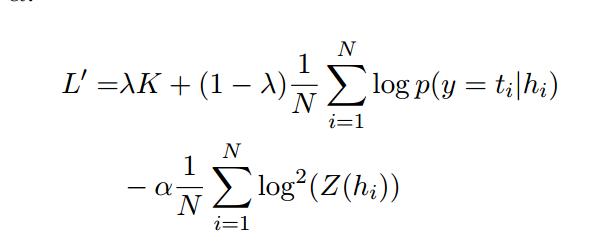
数据和评价
训练数据处理和来源:
来源:
- 新加坡国立大学学生英语语料库(the NUS
Corpus of Learner English (NUCLE) (Dahlmeier
et al., 2013)) - Lang-8学习者语料库(the Lang-8 Learner Corpora v2(Mizumoto et al., 2011)),Lang-8提取的是只学习英语的学习者的文本。
处理:
- 用语言识别工具langid.py(https://github.com/saffsd/langid.py)来获取纯净的英语句子
- 删除Lang-8中的噪声源-目标句子对( noisy sourcetarget sentence pairs),即其中源句子和目标句子长度的比率在[0.5,2.0]之外的句子对,或者它们的单词重叠比率小于0.2的句子对。
- 删除NUCLE和Lang-8中源句子或目标句子超过80个单词的句子对。
预处理后训练数据的统计见Table1: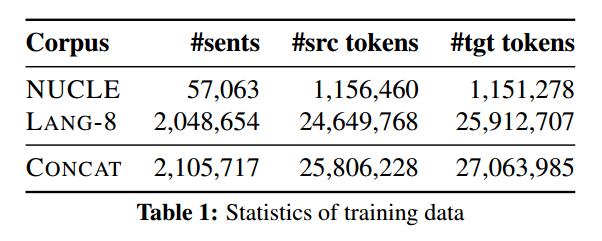
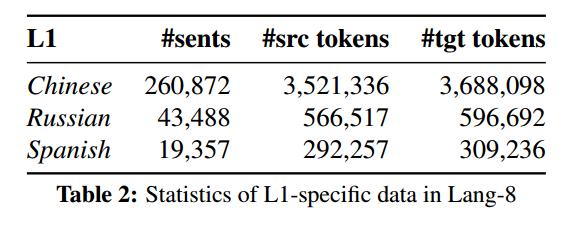
- 基于Lang-8中提供的L1信息获取的自适应L1-specific 域内信息。
- 每一个L1,它的域外数据是由除L1-specific域内数据在外的联合训练数据(CONCAT)中获取的。
开发测试集
从公共可用的 CLC-FCE 语料库中获取。FCE语料库包含由1,244位不同候选人在1,2000年和2001年参加剑桥ESOL英语第一证书(FCE)考试所写的1,244个脚本。根据脚本数量分成数量大致相等的两部分作为开发集和测试集。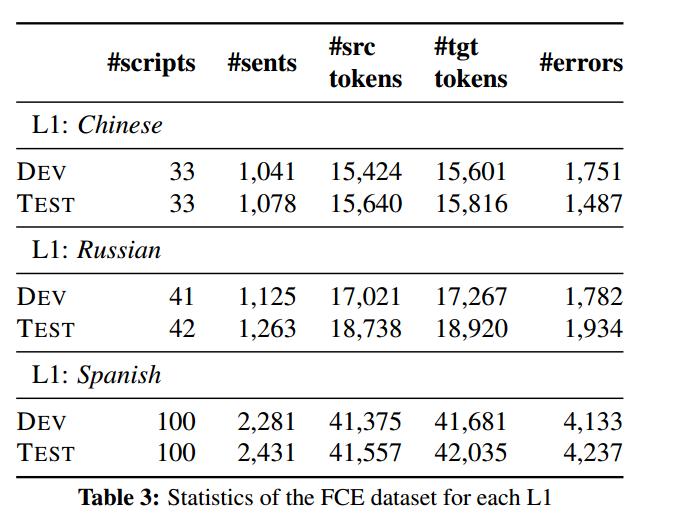
Evaluation
实验结果
Baseline SMT-based GEC sysytem
用Moses(Version 3)构建所有基于SMT的GEC系统。
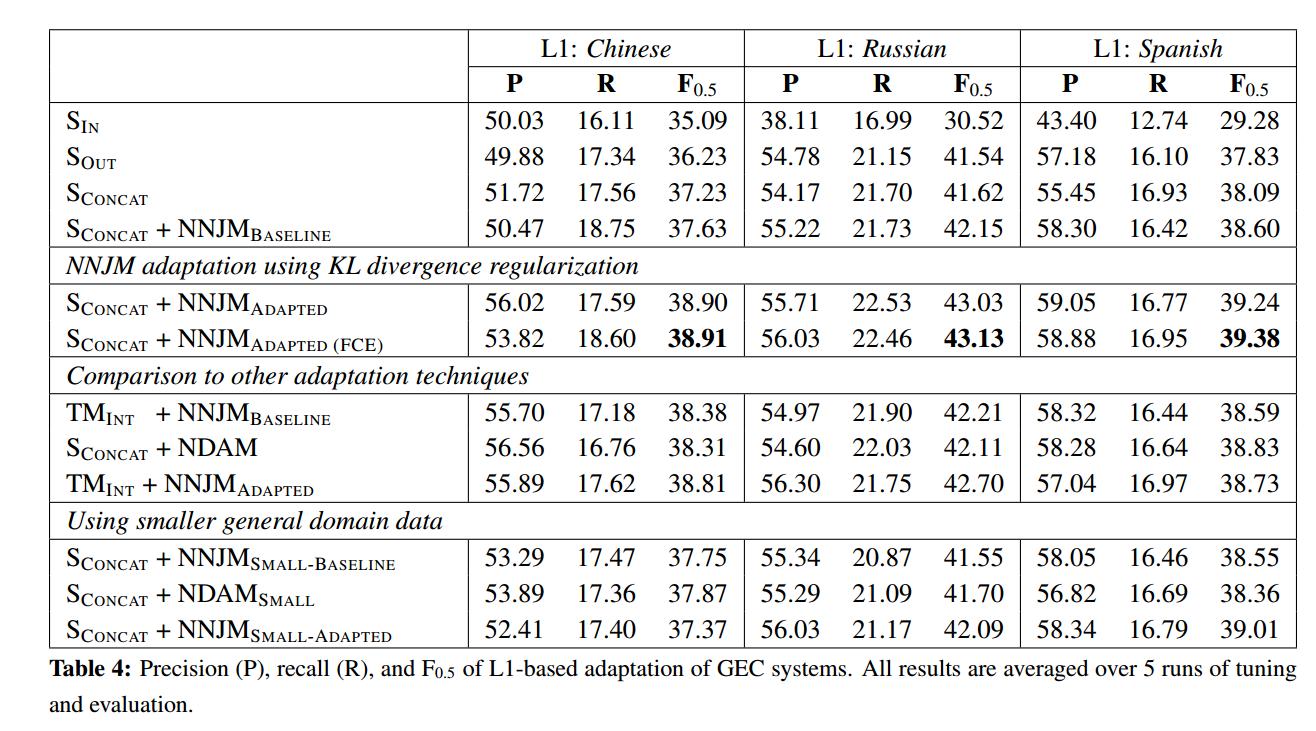
NNJM Adaptation
 :用全部的训练数据训练10个epoch。源上下文窗口大小设置为5,目标上下文窗口大小设置为4,形成一个(5+5)-gram的联合模型。使用一个mini-batch大小为128、学习率为0.1的随机梯度下降(SGD)进行训练。
:用全部的训练数据训练10个epoch。源上下文窗口大小设置为5,目标上下文窗口大小设置为4,形成一个(5+5)-gram的联合模型。使用一个mini-batch大小为128、学习率为0.1的随机梯度下降(SGD)进行训练。
Comparison to Other Adaptation Techniques
Effect of Adaptation Data
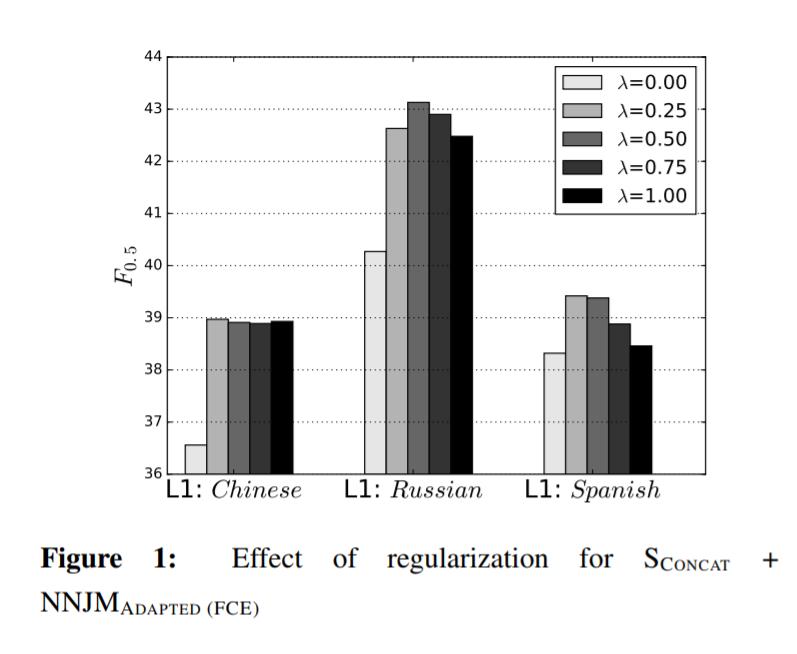
关于正则化的影响
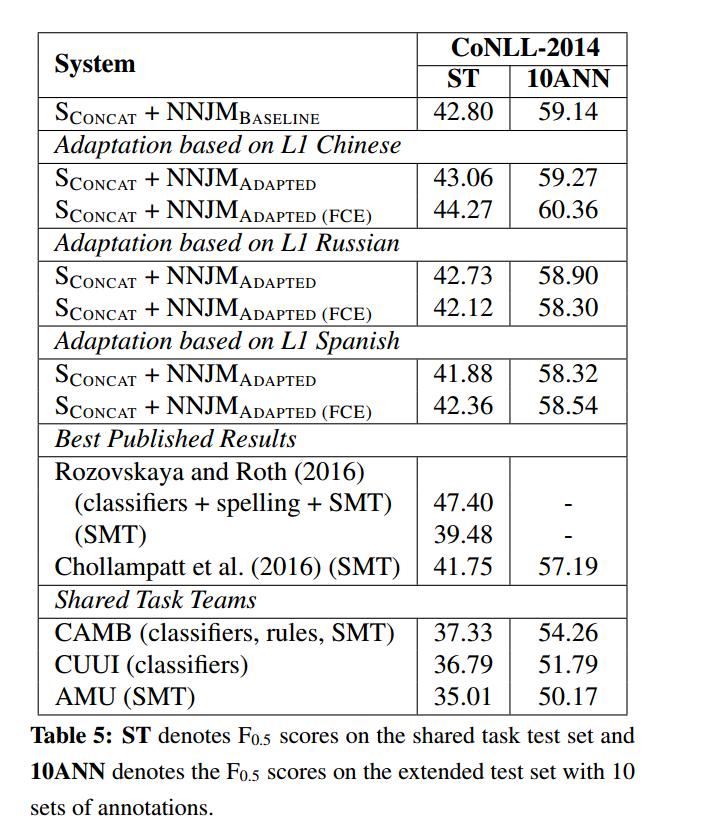
Evaluation on Benchmark Dataset
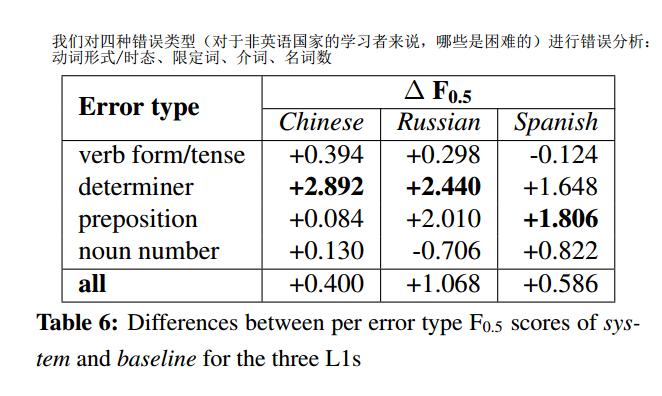
讨论和错误分析
相关工作
- HOO(Helping Our Own)和 CoNll共享任务 使得GEC变得普及流行。
- GEC已发表的相关工作旨在构建针对具体错误类型分类器和基于规则的系统,并将其结合构建成混合系统(hybrid systems)。
L1和L2间的跨语言影响主要用于母语识别任务,还用于类型学预测和ESL数据的预测误差分布。
- 最近,针对GEC提出了端对端(end-to-end)神经机器翻译框架,显示出了具有竞争力的结果。
- 本文中利用SMT方法和神经网络联合模型的优点,将基于L1背景的作者的NNJM模型整合到SMT框架中。通过KL离散正则化自适应来避免在较小的域内数据中的过拟合。
- SMT中其它调节技术包括混合建模(mixture modeling)和可选的解码路径(alternative decoding paths)。