
Fast and Robust Neural Network Joint Models for Statistical Machine Translation
NNJM:通过一个源上下文窗口扩展NNLM(which augments the NNJM with a source context window)。该模型是纯词汇化(purely lexicalized)的,可以集成到任何MT的Decoder中。具体来说,该模型利用m-word源窗口扩展一个n-gram目标语言模型。和以往的联合模型不同,该模型能够很容易作为一个feature被整合到任何SMT解码器中。

NNJM近似地估计了以源句子S为条件的目标假设T的概率。遵循目标的标准n-gram LM分解,其中每个目标字ti都受前面的n- 1个目标字的制约。为了使这个模型成为一个联合模型,对源上下文向量 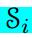 进行了条件分析:
进行了条件分析:
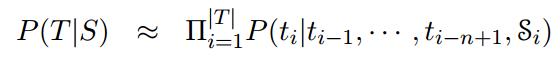
每一个目标词ti都直接对应着一个在位置ai的源词,是在以ai为中心的m-word的源窗口。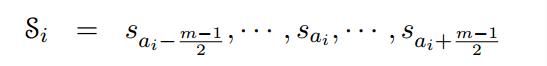
这种从属(affiliation)概念源自单词对齐,但与单词对齐不同,每个目标单词必须与一个非空(non-NULL)源单词相关联。

中文-英语平行句子的NNJM上下文模型例子如下图:

论文中采用的是n=4、m=11的15-gram LM 模型(神经网络语言模型能够优雅地扩展并利用任意大的上下文大小)。 论文中的神经网络结构与Bengio et.al等人的前溃神经网络语言模型结构基本相似,如下图。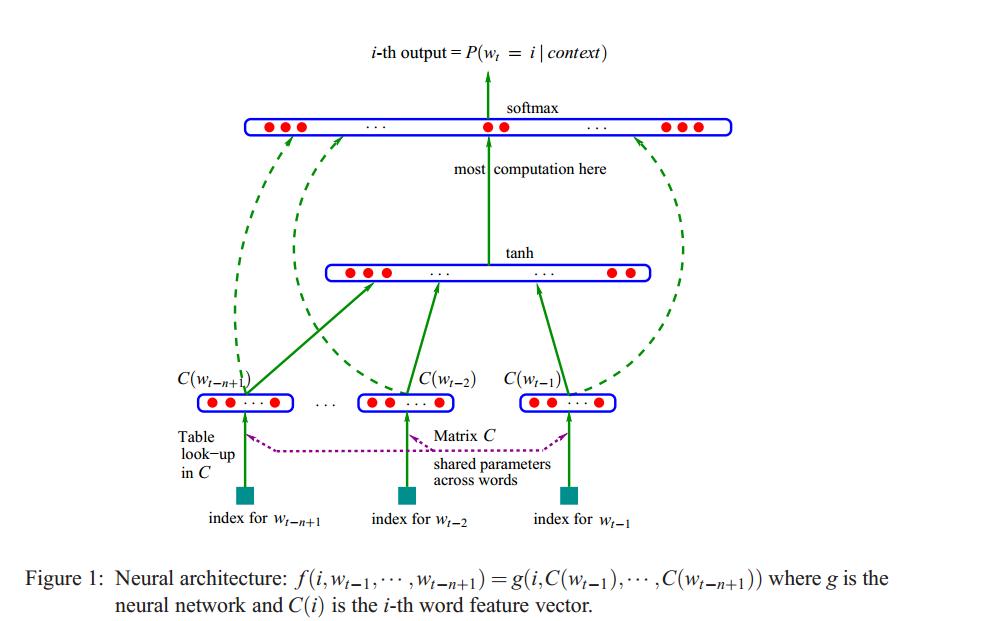
1. NNJM中的神经网络结构
NNJM中的神经网络架构与Bengio et al.(2003)所描述的原始前馈NNLM体系结构(feed-forward NNJM architecture)几乎相同。
隐藏层大小、词汇表大小和源窗口大小选择了这些值:

2. 神经网络训练
除了使用平行语料库代替单语语料库外,训练过程与NNLM相同。在形式上,我们寻求使训练数据的逻辑可能性最大化:

* 优化(Optimization): 带SGD的标准后向传播。
* 权重(Weights):[-0.05,0.05]之间进行随机初始化
* 学习率: 10^-3
* minibatch size: 128
* 20,000 minibatches/each epoch, 计算验证集的可能性。
* 40 epochs
* 我们在没有L2正则化或动量的情况下执行基本的权值更新。
* Training is performed on a single Tesla K10 GPU, with each epoch (128*20k = 2.6M samples)
3. Self-Normalized Neural Network
NNLM的计算成本在解码中是一个重要的问题,并且这个成本由整个目标词汇表上的输出softmax所支配。
我们的目标是能够使用相当大的且没有词类(word-classes)的词汇表,并且简单地避免在解码时计算整个输出层。为此,我们提出了自规一化(self-normalization)的新技术,其中输出层分数是接近于没有显示执行softmax的概率。
我们所定义的标准softmax对数似然函数如下:

由上看出,在解码阶段当log(Z(x))等于0时(Z(x)=1)我们就只需要计算输出层的r行而不是计算整个矩阵,但是很难保证用这个来训练神经网络,所以可以通过增加训练目标函数来明确鼓励log-softmax正态化器(explicitly encourage the log-softmax normalizer)尽可能接近0:
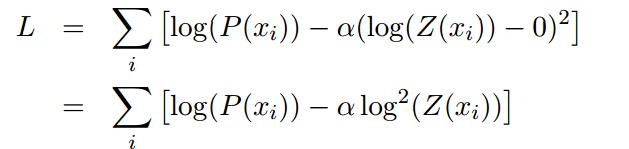
在这种情况下,输出层的偏置权值初始化为log(1/|V|),因此初始网络是自归一化的。在解码时,使用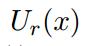 作为特征得分,而不是选用log(P(x))。在本篇论文中NNNJM结构中,在解码过程中,self-normalization将查找速度提高了15倍。
作为特征得分,而不是选用log(P(x))。在本篇论文中NNNJM结构中,在解码过程中,self-normalization将查找速度提高了15倍。

在用噪声对比估计( Noise Contrastive Estimation ,NCE)训练自归一化的NNLMs时虽然加速了训练时间,但是没有机制能控制自归一化程度。
4. Pre-Computing the Hidden Layer
自归一化显著提高了NNJM查找的速度,该模型仍比 back-off LM慢几个数量级。在这里,我们展示了预计算(Pre-Computing)第一个隐藏层的技巧,它进一步将NNJM查找速度提高了1000倍。
请注意,这种技术只会导致自归一化,前向反馈,有一个隐藏层的NNLM-style网络的显著加速。
5. Decoding with the NNJM
论文所提出的NNJM本质上是一个带有附加源上下文的n-gram NNLM,所以可以很容易地集成到任何SMT解码器中。
NNJM is fundamentally an n-gram NNLM with additional source context, it can easily be integrated into any SMT decoder。
主要介绍将NNJM集成到分层解码器时必须考虑的事项。
- Hierarchical Parsing(分层句法分析)
- Affiliation Heuristic(加入启发式)