
学习记录之句法结构标注(一)
Note:
- 关于学习者文本做句法标注
- 针对汉语学习者尚且没有太多工作,汉语上,香港城市大学有一些相关工作。
- 大致上是为中介语标注句法结构,进而可以做以下工作,例如给教师提供语言用例的检索、做中介语NLP等。
- 该篇文章仅是在阅读论文中所做的基础记录,大部分是论文翻译内容。
Information:
- 中介语(Interlanguage):也有人译为”过渡语”或”语际语”,是指在第二语言习得过程中,学习者通过一定的学习策略,在目的语输入的基础上所形成的一种既不同于其第一语言也不同于目的语,随着学习的进展向目的语逐渐过渡的动态的语言系统。
一、关于句法标注(Syntactically Annotating)
SALLE(Syntactically Annotating Learner Language of English)
从英语学习者文本的句法标注相关内容进行了解。该任务主要就是对把英语作为第二语言的学习者所写的文本进行句法结构标注。该项目中的目标是对给定句子中存在的语言属性进行注释(annotate linguistic properties present),而不是对学习者的意思做出太多解释(interpretation),或者正确的形式应该是什么。为了达到这个目的,我们的注释方案根据句子中的上下文,并基于英语规则(目标语言),添加了几个关于每个单词的语言信息。 我们通过对依存关系进行注解来标记句子中的单词之间的句法关系,例如,一个词是另一个词的主语。
A beta version of the guidelines we are using are available here.The decisions we have made (certainly needing refinement in some cases) point out many of the essential questions that need to be addressed for linguistically annotating learner data, and we hope they can stimulate discussion.
二、论文研读–《Universal Dependencies for Learner English》


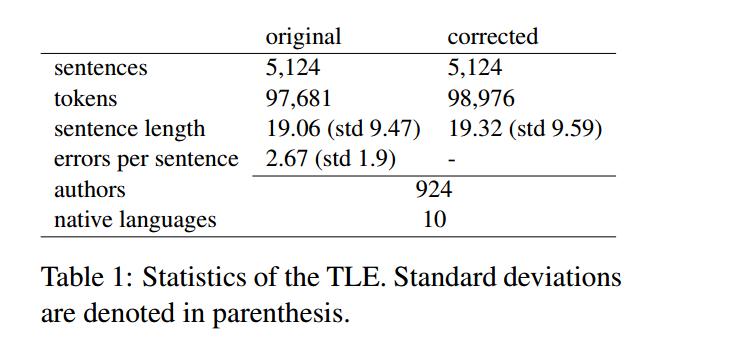
Abstract: 本篇论文主要介绍了英语学习者的树库(TLE),是一个将英语作为第二语言(ESL)的第一个公共可用的语法树库(syntactic treebank)。TLE为5124个句子提供了手动注释的POS标签和通用依存(Universal Dependency,UD)树,这些句子来源于剑桥大学FCE(First Certificate in English )语料库。UD注解和FCE中已存在的错误注解结合在一起,从而为每个句子的原始版本和错误修正后的版本提供完整的语法分析。进一步的描述了ESL注释指南,该指南允许对不符合语法的英语进行一致的句法处理。最后,在TLE数据集上对POS标记和依存关系解析性能进行基准测试,并测量语法错误对解析准确性的影响。我们设想树库支持第二语言习得的广泛的语言和计算研究以及自动处理不符合语法的语言。
1、Introduction
大多数世界范围内可用的英语文本都是由非母语者所产生的。这些文本中最明显的挑战就是语法错误,解决这些问题对于语言习得的科学研究和自然语言处理都是至关重要的。尽管非母语英语无处不在,但是目前还没有公共可用的ESL句法树库。
为了解决这个问题,我们提出了英语学习者树库(TLE,the
Treebank of Learner English),这是非英语母语的第一个资源,树库包含用POS标签和依存树手动注释的5,124个句子。
- TLE句子是从FCE数据集中获取,这些句子是由来自10个不同母语背景的英语学习者所写。
- treebank使用了通用依存(UD)形式主义,提供跨不同语言的统一注释框架,且面向多语种NLP。
以上两种使得treebank能够支持ESL的计算分析,它不仅使用基于英语的,而且还使用多种语言的方法,试图将ESL现象与本地语言语法联系起来。
- 以学习者语言分析之前的工作为基础,制定了一套附加的注解约定,旨在对不符合语法的学习者语言进行统一处理。采用一个two-layer 分析,在这个分析中,每个句子的原始版本和纠正版本都提供了不同的语法注释。该方法是通过FCE语料中已存在的错误注释而启用的,该注释用于生成数据集的错误修正变体。
总的来说这篇论文主要有以下三点贡献:
- 为ESL引入了第一个大型语法树库,该树库包括手工注释的POS标签和通用依存(UD)。
- 为不符合语法的学习者英语描述了一种受语言驱动的注释方案,并通过注释者间协议分析为其一致性提供经验支持。
- 作者在自己的数据集上对性能最佳的解析器进行了基准测试,并且评估了自动进行POS标注和依存分析的精确度对语法错误的影响。
论文结构说明:
- Section 2:Present an overview of the treebank.
- Section 3 and Section 4:Provide background information on the annotation project, and review the main annotation stages leading to the current form of the dataset.
- Section 5: To Summary the ESL annotation guidelines.
- Section 6: Present the Inter-annotator agreement analysis.
- Section 7: Parsing Experiments.
- Section 8: Related Work
- Section 9: Conclusion
2、Treebank概述
使用的是NLTL句子分词器(http://www.nltk.org/api/nltk.tokenize.html)的改编版进行句子级别切分。
Word level tokenization was generated using the Stanford PTB word tokenizer(http://nlp.stanford.edu/software/tokenizer.shtml)。
TLE是第一个以完全手动注释的方式构建的大规模英语树库。
- TLE包含5124个英语通用依赖关系(UD)形式中带有POS标记和依存注释的句子。这些句子是从FCE语料得到,这是一组中高级英语学习者所写的文章,包含75个错误分类的错误注释。
- 树库中的学习者来自10个母语不同的语言背景:汉语、法语、德语、意大利语、日语、韩语、葡萄牙语、西班牙语、俄语和土耳其语。每种母语背景下都随机挑选500个自动分段的句子,除此之外所选的句子必须至少包含一种不是符号或拼写的语法错误。
TLE注解有两个版本:
- 学习者写的原始句子(有语法错误);
- 纠正的句子,是原始句子的语法变体,根据FCE数据集提供的手动错误注释纠正了句子中的所有语法错误。
由此产生的正确句子构成了标准英语的平行语料库。
3、Annotator Training
手动注释人员的相关培训
4、Annotation Procedure
树库的形成分注释、审核、分歧解决和有针对性的调试四个步骤。
4.1、Annotation
- annotation from scratch.
我们使用一个基于CoNLL的文本模板(textual template),其中每个单词在单独的行(line)中进行注释,每一行包含六列(根据英语UD指南 Version 1):
- index(IND)
- the word itself(WORD)
- a Universal POS tag(UPOS)
- a Penn Treebank POS tag(POS)
- a head word index(HIND)
- a dependency relation(REL)

下图示例是展示给注释者的预先注释的原始句子:

4.2、review
所有带注释的句子以双盲的方式被随机分配给第二个注释器(也称 reviewer)。reviewer的任务是标记所有注释不同的注释。
为方便review的工作,编辑了一个常见的注解错误列表(可在已发布的注释手册中找到)。
引入了一个主动编辑注释的方案来进行review,该方案可以避免reviewer由于passive approval而忽略注释问题。具体来讲:

4.3、Disagreement Resolution
在注解过程的最后一步里,所有的annotator-reviewer分歧对由第三个注释器解决(annotator,henceforth judge),其主要任务是在annotator和reviewer之间做出选择。主要是以下两个任务:
- 评审人员可以用第三种替代方法解决注释或评论意见的分歧,并为审阅人员所忽略的注释问题引入新的更正。
- 另一项任务是为通过审查异议或出现在句子中的歧义结构标记可接受的替代注释(mark acceptable alternative annotations)。
4.4、Final Debugging
在采用过judge给出的解决方案后,我们用特定的语言学结构的调试测试对语料库进行了查询。附件的测试阶段进一步减少了注释错误的数量和treebank中的不一致性。
5、Annotation Scheme for ESL
注解使用英语的UD POS标记和依存关系的现有目录,并遵循英语的标准UD注释指南。这些指导方针是以英语的语法用法来制定的,不包括由于语法错误而产生的非标准句法结构。
指导方针遵循字面阅读(literal reading)的一般原则,强调根据观察到的语言使用进行句法分析。该策略延续了SLA中的一项工作,主张围绕形态语法表面依据对学习者语言进行集中分析。
我们的框架包含了对已改正的句子的并行注释,这种策略经常出现在多层注释方案的上下文中,这些注释方案也解释了错误修正的句子形式。
在UD中部署一个字面注释策略,这是一种加强注释跨语言一致性的形式主义,将使作者在英语中的非规范结构和作者的母语中的规范结构之间进行有意义的比较。因此,我们的树库的一个重要的新特性是它支持学习者语言的交叉语言研究的能力。
5.1 Literal Annotation
关于词性标注,文字标注意味着尽可能地遵循观察到的词形形式。
从句法上讲,参数结构是根据单词的用法进行注释的,而不是根据相关上下文中的典型分布进行注释的。
下面的惯例列表定义了一些常见的与语法错误相关的非规范结构的字面阅读的概念: 参数结构、时态、词性转换(构词法?)、
Argument Structure
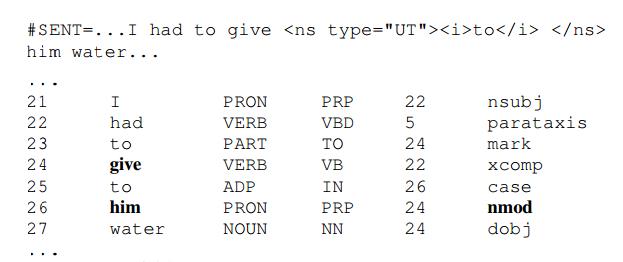
- Extraneous prepositions:我们注释所有由外来的介词作为名词修饰词引入的名词依赖性。在下面的句子中,“his”被标记为一个名词修饰语(nmod)而不是“give”的间接宾语(iobj)。
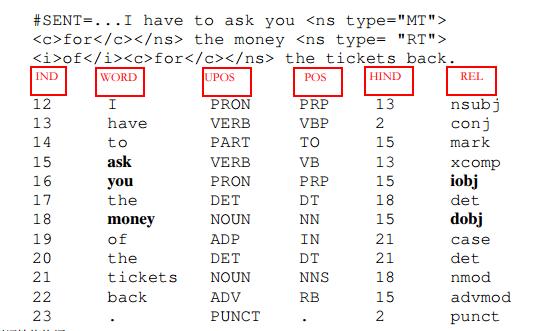
- Ommited prepossitions:我们把一个缺少介词的谓语词的名词依赖项作为参数,而不是名词修饰词。例如下面的例子中,将“money”作为一个直接宾语(dobj)而不是视为一个名词修饰语(nmod),“you”则根据上下文视为一个间接宾语(iobj)而不是一个dobj。
- Extraneous prepositions:我们注释所有由外来的介词作为名词修饰词引入的名词依赖性。在下面的句子中,“his”被标记为一个名词修饰语(nmod)而不是“give”的间接宾语(iobj)。
- Tense
根据动词的形态学时态,标注错误的时态用法。例如下图中,“shopping”的时态注释为现在分词(present participle)VBG,而校正后的“shop”则被注解为VBP。

- Word Formation
字面上注释了在语境上合理并且可以分配PTB标签的错误单词形式。下面例子中“stuffs”就是被视为一个复数名词处理。

类似地,在下面的示例中我们将“necessaryiest”注释为最高级(superlative)。

5.2 Exceptions to Literal Annotation
虽然ESL的一般注解策略遵循literal sentence readings,但是有几种类型的构词错误使这种阅读没有信息或不可能,本质上迫使某些词必须用某种程度的解释进行注释。
因此,根据从FCE错误纠正中获得的对预定义词的解释,在原句中注释下列情况。
- Spelling
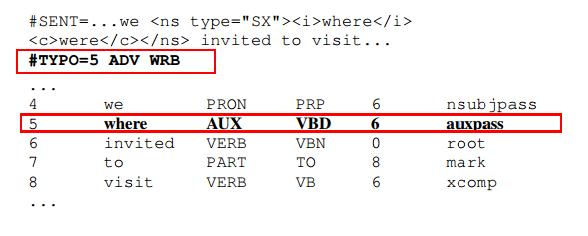
拼写错误是根据单词的正确拼写形式进行注解的。为了支持自动注释工具的错误分析,关于拼写错误的单词形式的最常见用法,在POS标签的元数据字段TYPO中注释恰好形成有效单词的拼写错误的单词。下图的例子中,TYPO字段包含“where”的典型的POS注释,这在句子的上下文中显然是无意的。
- Word Formation
不能使用现有的PTB标签分配的错误的词结构会被标注为正确的词形式。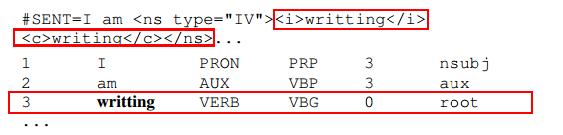
有复数后缀的畸形形容词会接收到一个标准的形容词POS标签。当适用时,这种情况还会在使用属性“ua”的错误注释中获得不必要的协议的附加标记。


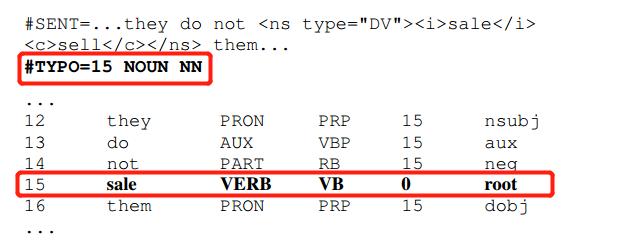
错误的构词法导致有效的,但上下文不可信的构词形式也根据词的更正进行注解。在下面的例子中,名词形式的“sale”很可能是一个畸形动词的意外结果。 与导致有效单词的拼写错误类似,我们在TYPO元数据字段中标记典型的文字POS注释。
6 Editing Agreement
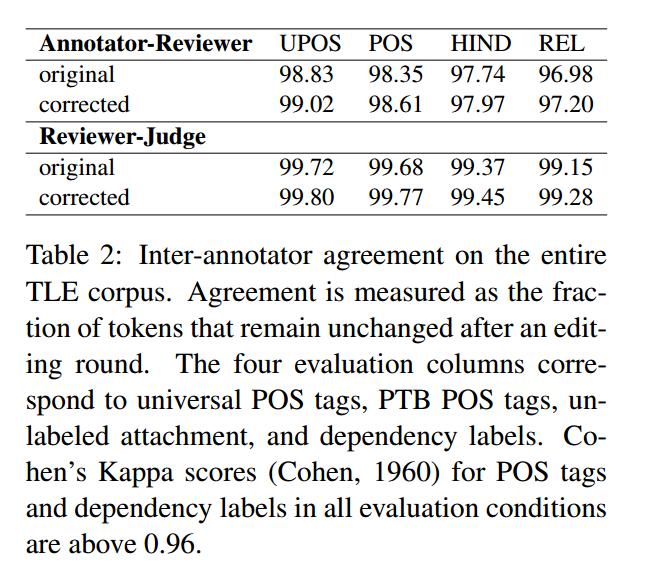
7 Parsing Experiments
TLE可以学习解析学习者语言并探索语法错误和解析性能之间的关系。因此,在数据集上提出了解析基准,并提供了几种评估语法错误降低了自动POS标记和依存解析质量的范围。
- 第一个实验:
- measures tagging and parsing accuracy on the TLE and approximates the gloabal impact of grammatical errors on automatic annotation via performance comparison between the original and error corrected sentence versions.