
Dependency Biaffine Attention Neural Dependency Parsing

摘要
本文主要针对 Dependency Parsing 提出了一个新的模型,该文以Kiperwasser & Goldberg (2016) 最近的工作为基础,在graph-based的dependency parser的基础上引入了 neural attention。
We use a larger but more thoroughly
regularized parserthan other recent BiLSTM-based approaches,with biaffine classifiers to predict arcs and labels.
本文针对任务:Dependency Parsing
【(1) 本文针对什么任务?任务简要介绍下。】
依存分析 (Dependency Parsing, DP) 通过分析语言单位内成分之间的依存关系揭示其句法结构。 直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。再通俗地讲:它将句子分析成一颗依存句法树,描述出各个词语之间的依存关系。
- 依存语法的结构没有非终结点,词与词之间直接发生依存关系,构成一个依存对,其中一个是核心词,也叫支配词,另一个叫修饰词,也叫从属词。
- 依存关系用一个有向弧表示,叫做依存弧。依存弧的方向为由从属词指向支配词,当然反过来也是可以的,按个人习惯统一表示即可。
- 依存句法分析的5个条件
- 一个句子中只有一个成分是独立的
- 句子的其他成分都从属于某一成分
- 任何一个成分都不能依存于两个或两个以上的成分
- 如果成分A直接从属成分B,而成分C在句子中位于A和B之间,那么,成分C或者从属于A,或者从属于B,或者从属于A和B之间的某一成分
- 中心成分左右两边的其他成分相互不发生关系
详细介绍:https://cl.lingfil.uu.se/~nivre/docs/ACLslides.pdf
本文发现了什么问题?该文大体是怎么解决的?解决得如何?
本文作者提出自己的问题:目前性能最优的基于转移(transition-based)的神经依存解析模型大大优于许多更简单的基于图(graph-based)的神经解析器。
解决方案:在Kiperwasser & Goldberg (2016) 所提出的模型的基础上加以改进:
- 建立了一个更大的网络,但也使用了更多的正则化
- 用双仿射分类器(Biaffine Classifier)代替传统的基于MLP的注意机制和仿射标签分类器(Affile Label Classifier),而不是在双仿射变换中使用LSTM的顶部递归状态
- 在两种不同的模型架构和超参上训练模型,加以比较和改进
结果:得到的解析器保持了Graph-based的方法的大部分简单性,同时又接近了SOTA Transition-based的方法的性能。
解释下题目。题目起得如何?能概括内容并吸引人吗?
Biaffine Attention – 简单明了
介绍
这个任务以往是如何解决的?作者沿着哪条路径继续研究的?为什么?
Dependency Parsing主要有两种方法:Transition-based 和Graph-based。作者沿着Graph-based这个角度对Parser的结构加以改进(引入Biaffine Attention)从而达到提升性能的目的。目的即上文提出的当前Graph-based的Parser性能低于Transition-based的性能。
下面从对Paser的两种结构的研究过程进行介绍:
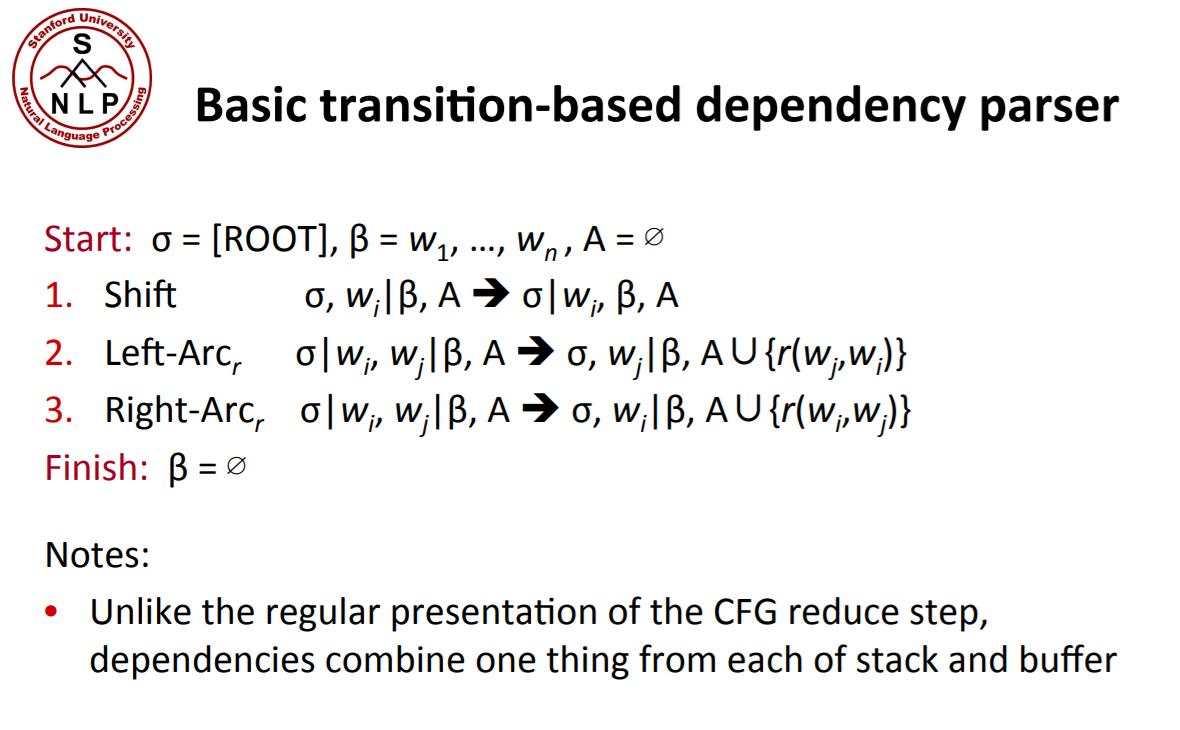
Transition-based Parser
About
基于转移的解析器从左到右按顺序处理句子中的每一个词,每次选择一条弧来构成一颗解析树。包含一个尚未解析的单词的“缓冲区(buffer)”和一个未看到head或者依赖项尚未被全部解析的单词的“堆栈(stack)”。
在每个步骤中,Transition-based解析器都可以访问和操作堆栈和缓冲区,并将弧从一个单词分配到另一个单词
然后,可以根据从堆栈、缓冲区和以前的arc操作中提取的特征训练任何多类机器学习分类器,以预测下一步操作。
Transition-based的解析器不使用机器学习来直接预测边;他们用它来预测转移算法的操作。
- Modifies
- Chen & Manning(2014)首次成功地尝试将深度学习集成到Transition-based依存解析器中。
- 每个step中,(前馈)网络根据来自堆栈和缓冲区中特定单词的单词、标记和标签嵌入,为解析器可以采取的每个操作分配一个概率
- Weiss et al. (2015) and Andor et al. (2016) :增加了一个波束搜索(beam search)和条件随机场(CRF)的损失目标,使解析器一旦发现以前的操作可能是不正确的苗头便可以“撤消”这个操作。
- Dyer et al. (2015) and (Kuncoro et al., 2016) :使用LSTMs来表示堆栈和缓冲区,通过以组合已解析的短语的方式构建来获得最优性能。
- Chen & Manning(2014)首次成功地尝试将深度学习集成到Transition-based依存解析器中。
Graph-based Parser
About
Graph-based的解析器使用机器学习方法为每条可能的边分配一个权重或概率,然后从这些加权边中构造一棵最大生成树(Maximum Spaning Tree, MST)
基于图的依存句法分析就是为每个要分析的句子生成一个有向图,其中:节点是句子中的单词,边是单词之间的依存关系,因为依存句法中规定每个句子都有其核心成分,所以加入了须根节点。依存句法中还规定了句子中除了须根节点,每个词必须依存于其他词,因此,句子依存图中边的个数和单词的个数相等。
Modifies
Kiperwasser & Goldberg (2016) :提出一种基于神经图的解析器(除了Transition-based的解析器之外),它使用与Bahdanau等人(2014)所提出的相同的注意机制来进行机器翻译。每个单词的(双向)LSTM递归输出向量与它每个可能的head递归向量串联拼接,并将结果用作MLP的输入,MLP对每个生成的弧进行评分。训练时预测的树结构是每个单词都依赖于其得分最高的头部。类似地生成标签,在多分类MLP中使用每个单词的循环输出向量及其gold或预测的head word的循环向量。
Labels are generated analogously, with each word’s recurrent output vector and its gold or predicted head word’s recurrent vector being used in a multi-class MLP
Hashimoto et al. (2016) :在它们的多任务神经模型中包含一个基于图的依存解析器。用双线性(bilinear)(但仍然使用MLP标签分类器)替代了Kiperwasser和Goldberg(2016)使用的传统的基于MLP的注意力机制。
Cheng et al. (2016) :在某种程度上,试图绕过其他Graph-based的神经解析器的限制,这些解析器无法根据以前的解析结果决定每个可能弧的得分。除了用一个双向循环神经网络来计算每个词的循环隐层状态向量以外,还有附加的单向循环神经网络(left-to-right和 right-to left)来记录之前每条arc的概率,然后用这些概率一起来预测下一个arc。
目前摘要存在什么问题?为什么?你觉得可能还存在什么其他问题?为什么?
摘要中没发现提出问题,只表述了当前论文的工作和取得的成绩。暂时还未发现什么特殊的问题。
该文准备如何解决这个问题?为什么可以这样解决?你觉得该文解决这个问题的方法如何?为什么?你觉得可以如何/或更好的解决这个问题?为什么?
通过对以往在Graph-based Parser的结构进行性能分析,加以整合改进,提出了Biaffine Attention机制。有效的提高了当前Graph-based Parser性能,几乎与当前SOTA的Transition-based Parser效果相当。
列出该文贡献(该文自己觉得的)
- 提升了基于简单的Graph-based神经解析器的性能,该解析器在六种不同语言的标准树库上获得了最先进或接近最先进的性能,在英语PTB上实现了95.7%的UAS和94.1%的LAS,在Chinese Penn Treebank中实现了UAS=89.30%,LAS=88.23%。
- 目前Graph-based解析器中性能最高的。
- 分析了超参的选择对于解析结果的准确性。
Model
模型
将Kiperwasser & Goldberg (2016),Hashimoto et al. (2016), and Cheng et al. (2016)提出的模型加以变形:
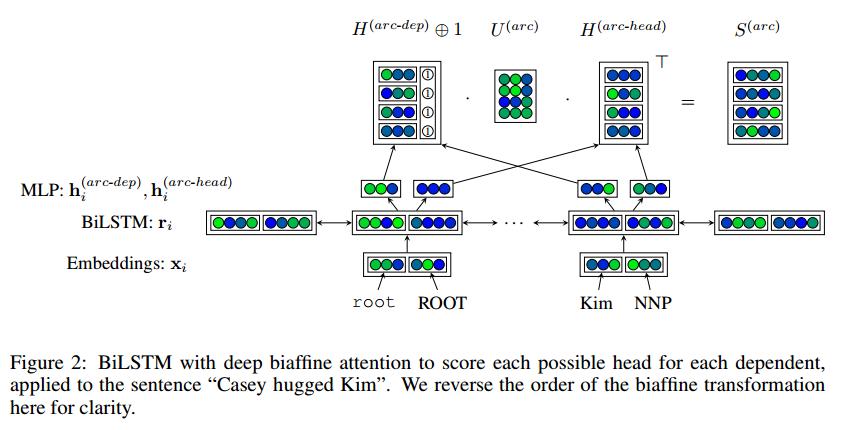
模型创新点
- 使用双仿射注意力机制(Biaffine Attention)代替双线性(bilinear)或传统的MLP-based的注意力机制, 结构更加简单,运用了一个双线性层而不是两个线性层和一个非线性层—选择双仿射使得我们模型中的分类器类似于传统的仿射分类器,后者在单个LSTM输出状态$$ \mathbf{r}_i$$(或其他向量输入)上使用仿射变换来预测所有类的得分向量$$ \mathbf{s}_i $$。
- 使用Biaffine依存项标签分类器
- 在应用双仿射变换(Biaffine transformation)之前,我们将降维MLPs应用于每个递归输出向量 $$ \mathbf{r}_i $$。
详细介绍模型,从输入到输出,输入矩阵维度,公式等
可将双仿射注意力机制看作一个传统的放射分类器,但是使用堆叠LSTM的输出$ \mathbf{R} \mathbf{U}^{(1)}$的一个 (d×d)线性变换代替权重矩阵W,用一个(d×1)变换$ \mathbf{R} \mathbf{u}^{(2)} $来替代偏置项b。
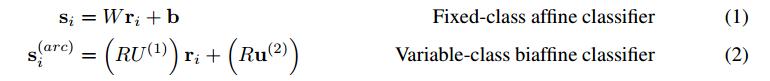
这在概念上的优势是,可以直接在对单词 j 在术语$$ \mathbf{r}_j^T u$$中接收任何dependents的先验概率 和 j 在$$ \mathbf{r}_j^T \mathbf{U}^{(1)} \mathbf{r}_i $$中接受特定依存项 i 的可能性之间进行建模。还使用双仿射分类器来预测给定的head或预测head $ {y}_i $的依存标签(3)。
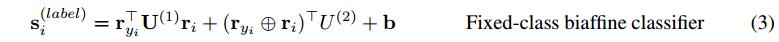
同样地为每个类的每个先验概率建模:
只给出一个词 i 的可能性(一个词带有一个特定的标签的概率为多少),
只给出head word $$ y_i $$的可能性(一个词带有一个特定标签的依存项的概率为多少),
- 给出单词 i 和它的head的类的可能性(给定一个单词的head,且该单词带有某个特定标签的概率为多少)。
在Biaffine分类器之前将较小的MLPs应用于循环输出状态,其优点是可以剥离与当前决策无关的信息。
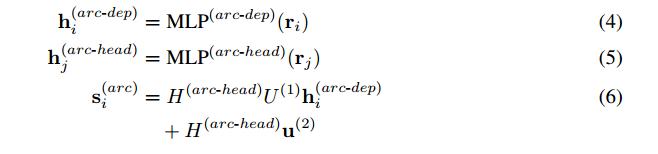
在标签分类器中使用递归状态之前,还将MLP应用于递归状态。和其它Graph-based模型一样,在训练时,预测的解析树是每一个单词都依存于其得分最高的head(虽然在测试时也会通过MST算法确保解析树是一个格式良好的树)。
除了和其他Graph-based解析器之间存在架构差异之外,作者还做出了一些超参数选择,使得解析器性能优于其他解析器。

| Hyperparameters | Decriptions |
|---|---|
| 外部词向量 | 计算一个在训练数据集中至少出现两次的单词组成的“训练过的”embedding矩阵,并将这些embedding添加到它们相应的预先训练过的embedding中。任何不在这两种嵌入矩阵中出现的单词都将由一个OOV符号替换。100维 |
| POS tag vectors | 100d |
| three BiLSTM layers | 400 dimensions in each direction |
| ReLU MLP Layers | 500 and 100 dimensions |
Experiments
数据集及评价标准介绍
English Penn Treebank
- 采用版本为3.3.0和3.5.0的Stanford Dependency转换工具将PTB数据集转换为PTB-SD 3.3.0和PTB-SD 3.5.0两个版本。
- POS标签:Stanford POS tagger 生成
Chinese Penn Treebank
- POS tags:Gold tags
- CoNLL2009 shared task dataset
- POS tags:提供的预测标签
注意:在评估PTB-SD和CTB时省略标点符号
通过PTB-SD 3.5.0验证集来实现超参搜索,为最小化到PTB-SD 3.3.0基准测试的过度拟合。在PTB-SD 3.5.0测试集上来进行超参分析。
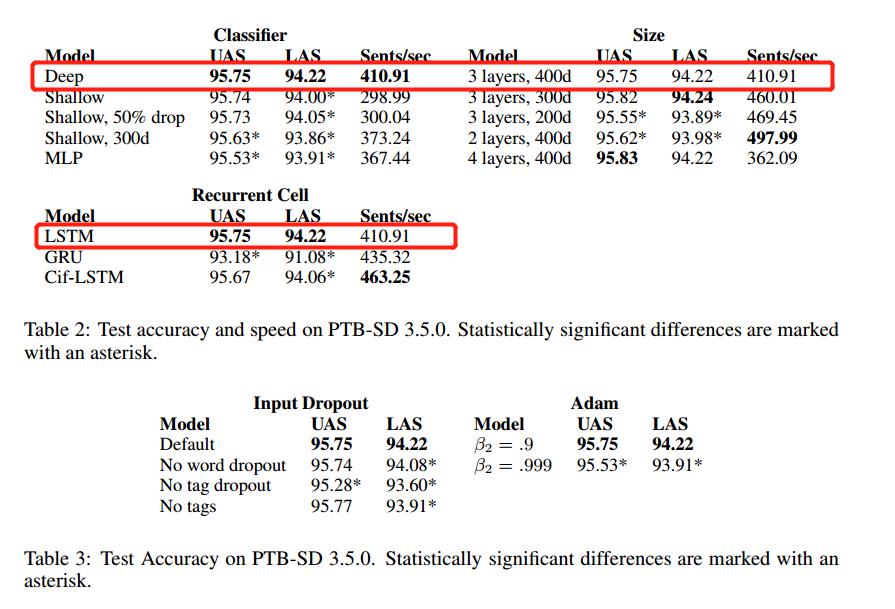
超参选择
- Attention机制
研究了不同分类器对准确度和性能的影响,发现:深层双线性模型在速度和精度方面都优于其他模型。
其中,浅层双线性的arc和label分类器在与深层双线性模型设置相同时,两者UAS性能相当(deep: 95.75%, shallow:95.74%)。但是由于label分类器较大 ($$ {801 < c < 801} $$),所以解析过程中速度慢且发生过拟合。解决过拟合的方法有两种:
(1)增大MLP的dropout – 对解析速度并无改善;
(2)将recurrent cell大小降到300 – 这将降低UAS的准确性,也不会提升解析速度到论文中提出的deep模型中。
结果:实现了Kiperwasser & Goldberg (2016) 提出的基于MLP的注意力和分类方法,发现在LAS和UAS的准确性方面都明显低于deep biaffine方法。
Network Size
那么网络大小是如何影响速度和准确性的?
- Kiperwasser & Goldberg’s 2016:两层维度为125的BiLSTM
- Hashimoto et al.’s 2016:一层100维的BiLSTM用于解析过程(两个较低的层也被训练用于其他目标)
- Cheng et al.’s 2016:一层368维的GRU
结论:使用三层或四层比使用两层可以获得更好的性能,并将LSTM大小从200增加到300或400个维度同样显著地提高了性能。BUT:具有400维递归状态的模型在验证集上的性能显著优于300维模型,但在测试集上则不是这样。
Recurrent Cell
虽然GRU( Cheng et al, 2016)比LSTM的结构简单速度更快,但是在作者提出的模型中,GRU的表现不如LSTM的好。
Greff et al. (2015) 提出的Cif-LSTM(the coupled input-forget gate LSTM cells)模型的性能仍然略低于LSTM,但两者之间的差异要小得多,但是速度比GRU快。
猜想:Cif-LSTM模型中的输出门能够保证稀疏的递归输出状态,这有助于设定较高的dropout,以防止GRU无法做到的过度拟合。
Embedding Dropout
由于解析性能的提升,所以还需增加正则化(regularization)。
- 输入层进行了正则化
- 在训练过程中减少了33%的单词和33%的标签
- 只用单词或标签dropout来训练的模型,两者都没有明显地过拟合,后者使得label准确度和attachment准确度都有所降低。
结论:不使用任何tags却比使用tags dropout的性能更好。
Optimizer
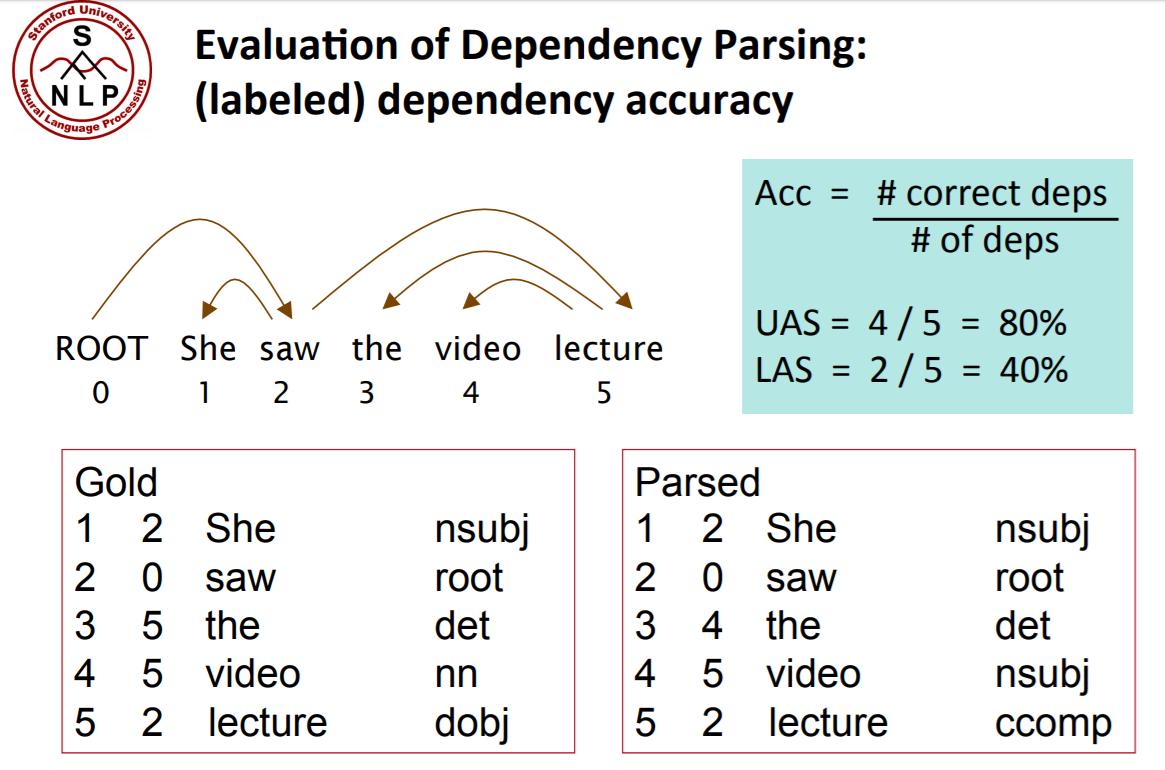
对每个单词标上序号(从1开始,0为“ROOT”),列出每个依存关系对应的序号和类型。分为两种正确率的计算。
- UAS:不考虑标签只考虑弧。
- LAS:同时考虑标签和弧。
Baseline介绍
结果分析
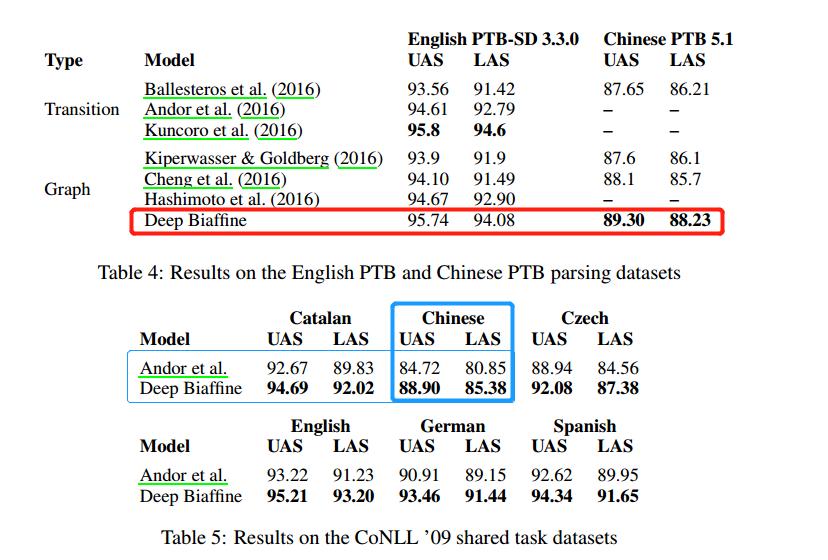
虽然Deep Biaffine模型结构要简单得多,但是在PTB-SD 3.3.0上的UAS性能几乎与Kuncoro等人(2016)提出的模型相同。
在CTB 5.17和CoNLL 09所有语言上的UAS也是最佳性能。
- 但是,CoNLL 09数据集包含许多非投射(non-projective )依存项,这些依存项很难或不可能通过基于转移的解析器预测出来。所以这也解释了本文提出的模型和Andor等人(2016) 的模型在这个数据集上差异较大的情况。
针对上述所提出的对于非投射情况的解析,Graph-Based具有优势,而在中介语的依存句法解析中,显然Graph-Based更适用。这也是接下来需要跟进的地方。目前对该模型进行了复现,在CTB数据上经过测试,UAS达到88+(忘记具体数字了,后面补上)。
LAS的结果较低:
Firstly, it may be the result of inefficiencies or errors in the GloVe embeddings or POS tagger, in which case using alternative pretrained embeddings or a more accurate tagger might improve label classification.
Secondly, the SOTA model is specifically designed to capture phrasal compositionality; so another possibility is that ours doesn t capture this compositionality as effectively, and that this results in a worse label score. Similarly, it may be the result of a more general limitation of graph-based parsers, which have access to less explicit syntactic information than transition-based parsers when making decisions.
要想解决以上两种限制性因素,需要一个相较于当前结构简单的Graph-based神经解析器更具创新性的模型。不过在我对于中介语的解析中,不考虑标签类别,所以对LAS无要求….
Conclusion
你觉得这篇paper创新与贡献是(不一定如作者所说)?为什么?
- 在神经依存解析器加入BIaffine Attention,希望在不影响性能的前提下提高解析速)。
- Larger and more Regularied Network, and SOTA Performance
有没有进一步深入的价值?为什么?”><a href=”#有没有进一步深入的价值?为什么?
虽然Graph-based Parser目前与 SOTA Transition-based Parser的性能相当,在English Penn Treebank上达到UAS 95.7%,但是在LAS上还有差距,另外在Chinese Penn Treebank上UAS=89.3%,都有进一步研究的价值。
列出该文弱点(或者是你觉得应该是什么问题,他解决的不好,你会如何解决?)
没有发现,没有什么想法…..
该文对你的启发是?
- 超参的设置与选择进行了比较详细的分析,为我接下来的实验提供了一些经验帮助。
- 我将使用该模型应用于对中介语依存结构的解析中,虽然希望改进模型,但是对于模型改进毫无思路。。。。。。。。
列出其中有价值的需要进一步阅读的参考文献
- Daniel Andor, Chris Alberti, David Weiss, Aliaksei Severyn, Alessandro Presta, Kuzman Ganchev, Slav Petrov, and Michael Collins. Globally normalized transitionbased neural networks. In Association for Computational Linguistics, 2016. URL https://arxiv.org/abs/1603.06042
- Adhiguna Kuncoro, Miguel Ballesteros, Lingpeng Kong, Chris Dyer, Graham Neubig, and Noah A. Smith. What do recurrent neural network grammars learn about syntax? CoRR, abs/1611.05774, 2016. URL http://arxiv.org/abs/1611.05774
- Danqi Chen and Christopher D Manning. A fast and accurate dependency parser using neural networks. In Proceedings of the conference on empirical methods in natural language processing, pp. 740–750, 2014