
Deep contextualized word representations (ELMO)
[TOC]

1. 题目与摘要
本文针对什么任务?任务简要介绍下。
- 任务: 词表征(Word Representation)
- 任务介绍: 句子是序列化,里面携带了大量的信息。在NLP发展的进程里面, 采用了one-hot vector的形式来表示一个句子里面的词是一种方式。表示这个句子的方式如下:
- 首先是创建一张词汇表(Vocabulary),然后每个词都有对应的位置,假设现在我们有10000个单词。本例子来自于吴恩达的Deeplearningai。图中所示的词汇表大小就是10000。

- 将句子里面的每个单词转换为one-hot vector。one-hot vector从字面上来理解就是向量里面只有1个1,也就是找到这个词在词汇表里面的位置处填上1,然后其他的位置都是0。可以看出one-hot vector的模长为1。
one-hot vector表示向量的缺陷:
这种表示把每个词都孤立出来了,使得算法对相关词的泛化能力弱。两个不同人名的one-hot vector的内积为0,这样来表示就不能体现出词汇在某些方面的相关性。
- 首先是创建一张词汇表(Vocabulary),然后每个词都有对应的位置,假设现在我们有10000个单词。本例子来自于吴恩达的Deeplearningai。图中所示的词汇表大小就是10000。
1 | (x\_Harry)^T * x\_Hermione = 0 |
本文发现了什么问题?该文大体是怎么解决的?解决得如何?
本文提出了一种新的深层上下文的word reresentation。这种模型不仅能够【1】表征词汇使用的复杂特性(例如句法和语义层面的特征,syntax and semantics);还能【2】表征出如何随着上下文语境的变化而改变,例如一词多义(polysemy)。
- 发现问题&解决:作者认为认为好的word representation模型应该同时兼顾【1】【2】两个特点,因此提出了deep contextualized word representation方法来解决以上两个问题。
- 本文中的模型本质上是一个基于大规模语料训练后的深层双向语言模型(biLM)内部隐状态的学习函数。
- 实验证明,新的词向量模型能够很轻松的与NLP的现有主流模型相结合,并且在六大NLP任务的结果上有着显著的提升。同时,作者也发现对模型的预训练是十分关键的,能够让下游模型去融合不同类型的半监督训练出的特征。
解释下题目。题目起得如何?能概括内容并吸引人吗?
2. 介绍
这个任务以往是如何解决的?作者沿着哪条路径继续研究的?为什么?
之前提出的方法从以下两个方面克服了传统词向量的一些缺点:
- 通过subword信息丰富词向量
- 为每个单词的词义学习单独的向量
最近的工作也主要集中在学习与上下文相关的表示:
- context2vec (Melamud et al., 2016):使用BiLSTM对一个中心词的上下文进行编码。
学习contextual embeddings的其他方法包括表示中的中心词本身,并使用监督神经机器翻译(MT)系统或者无监督语言模型(Peters et al., 2017)的编码器进行计算。
但是上面这两种方法都比较适用于大型数据集,但是MT方法受到并行语料库大小的限制。
在本文中,作者充分利用了丰富的单语数据,将biLM训练在一个包含约3000万个句子的语料库上(Chelba et al.,2014)。还将这些方法推广到深层上下文表示,这些方法可以很处理各种NLP任务。
本文提出了一种新的、能解决当前两个问题的深层上下文的word reresentation,每个word representation是整个输入语句的函数。在大型文本语料库上,以language model为目标训练出bidirectional LSTM模型从而产生词语的表征。
以前的工作也表明,不同层次的深度biRNNs编码不同类型的信息。
目前作者研究存在什么问题?为什么?你觉得可能还存在什么其他问题?为什么?
该文准备如何解决这个问题?为什么可以这样解决?你觉得该文解决这个问题的方法如何?为什么?你觉得可以如何/或更好的解决这个问题?为什么?
本文中的Word Representation不同于传统的word type embeddings:
- 作者提出的word representation:每个词都被分配了一个表示,每个word representation是整个输入语句的函数。
- 在大型文本语料库上,以language model为目标训练出bidirectional LSTM模型,然后利用BiLSTM产生词语的表征。ELMo故而得名(Embeddings from Language Models)。
- 与以前学习上下文词向量的方法不同,ELMo表征是“深层”的,也就是说它们是biLM的所有内部层表征的函数。
- 本文还通过使用字符卷积从子单词单元中获益,并且还无缝地将多义信息(multi-sense)合并到下游任务中,而不需要显式地训练来预测预定义的义类
这样做的好处是能够产生丰富的词语表征。高层的LSTM的状态可以捕捉词义中和语境相关的那方面的特征(比如可以用来做语义的消歧),而低层的LSTM可以捕捉到句法方面的特征(比如可以做词性标注)。如果把它们结合在一起,在下游的NLP任务中会体现优势。
列出该文贡献(该文自己觉得的)
- ELMO可以很容易地添加到现有的模型中
- 用于解决6个不同且具有挑战性的语言理解问题(包括文本蕴涵、问题回答和情感分析),仅添加ELMo表示就可以显著提高每种任务的结果,包括减少20%的相对错误。
- 对于可能进行直接比较的任务,ELMo的性能优于CoVe (McCann et al., 2017), CoVe使用神经机器翻译编码器计算上下文表示。
- 最后,对ELMo和CoVe的分析表明,深度表示优于仅来自LSTM顶层的表示。
3. 模型:ELMo(Embeddings from Language Models)
与大多数广泛使用的词嵌入(Pennington et al., 2014)不同,ELMo词表示是整个输入语句的函数。
它们是在具有字符卷积的两层biLMs之上计算的(第3.1节),作为内部网络状态的线性函数(第3.2节)。这种设置使得可以进行半监督学习,其中biLM被大规模地预先训练(第3.4节),并且很容易地融入到现有的广泛的神经NLP体系结构中(第3.3节)。
整体介绍(主要是图)
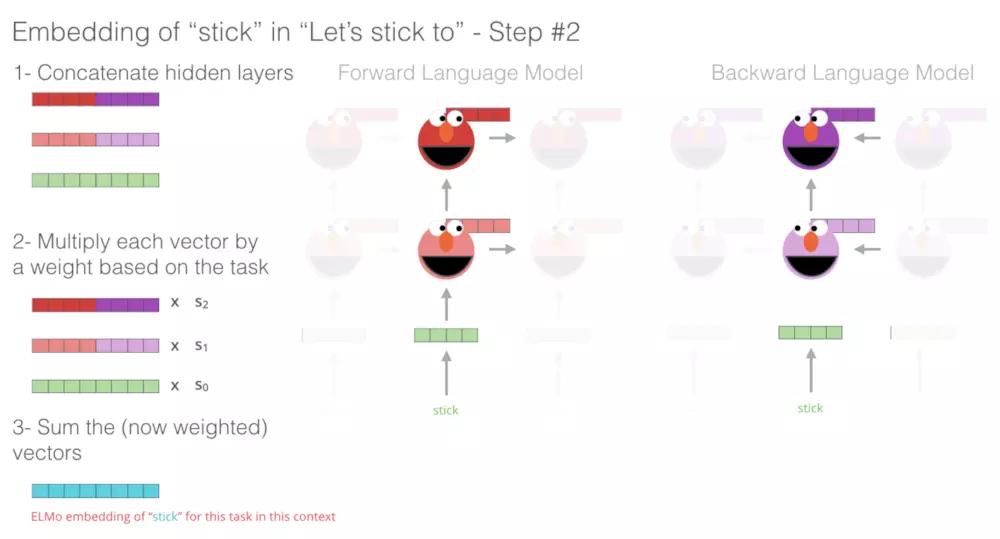
ELMO(Embeddings from Language Models)模型本质是从语言模型而来的。
- Language Model
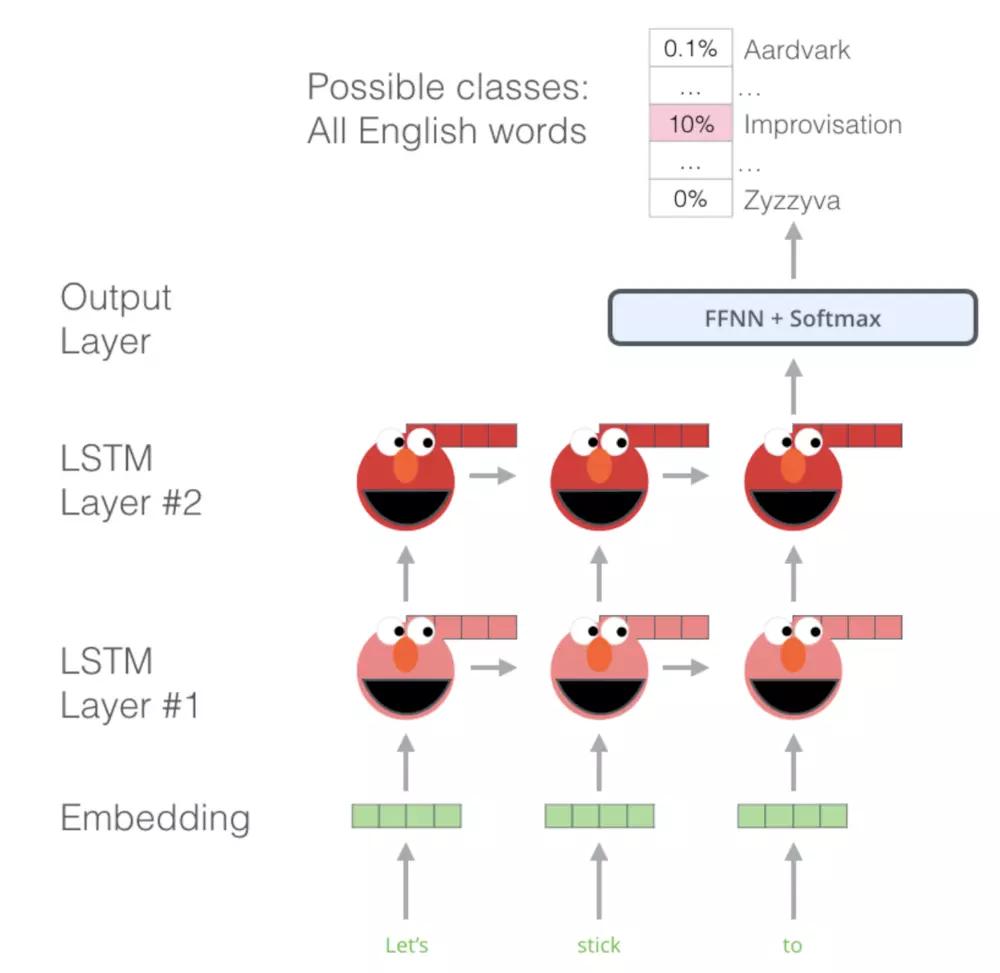
给定一个句子($t_1, t_2, t_N$) 构建的语言模型就是通过一个词汇的上下文去预测一个词$t_k$:
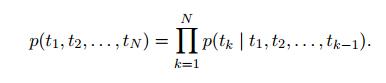
最新的神经语言模型(Jozefowicz et al. ´ , 2016; Melis et al., 2017; Merity et al., 2017)先 计算一个与上下文无关的字符表示 ${x_k^{LM}}$ (通过token embedding或者一个CNN覆盖字符),然后将它传递进L层前向LSTM。在每个位置k,每个LSTM层输出一个上下文相关的表示$\overrightarrow{h}_{k,j}^{LM}$,其中j = 1,…,L。顶层LSTM输出,$\overrightarrow{h}_{k,j}^{LM}$通过一个Softmax层用于预测下一个token$t_{k+1}$。
反向LM与前向LM类似,只是它以相反的方式遍历序列,根据未来上下文预测前面的token。
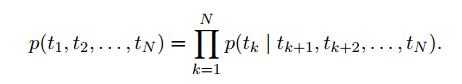
biLM结合了前向LM和反向LM。我们的公式共同最大化了前向和反向的对数似然性:
$$
\sum_{k=1}^N(\log p(t_k | t_1,…,t_{k-i}; \circleddash_x, \overrightarrow{\circleddash}_{LSTM}, \circleddash_s) + \log p(t_k | t_{k+1},…,t_{N}; \circleddash_x, \overleftarrow{\circleddash}_{LSTM}, \circleddash_s)))
$$
Bidirectional Language Model
其中两个方向的LSTM的参数不是共享的,$\circleddash_x$就是一开始输入的词向量,$\circleddash_s$就是softmax层参数。因此,双向语言模型的结构图,可以表达如下:
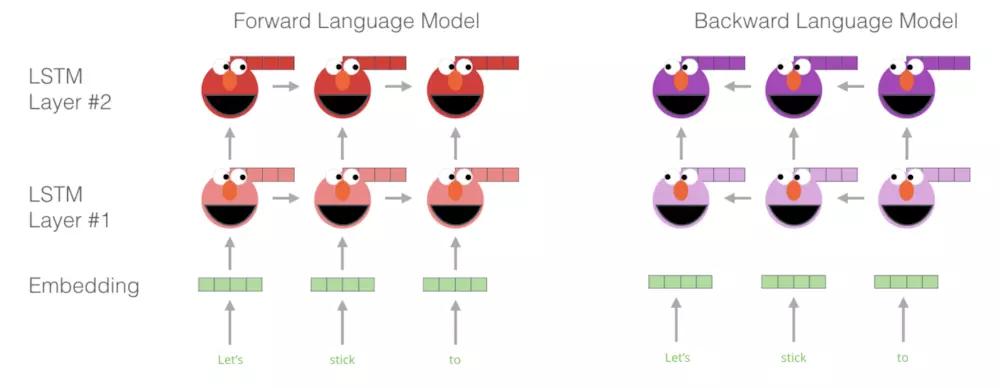
- ELMO:一种学习单词表示的新方法,该方法是biLM层的线性组合。具体的描述在模型创新点。
模型创新点
(仅对要进一步跟进的paper)详细介绍模型,从输入到输出,输入矩阵维度,公式等
ELMo is a task specific combination of the intermediate layer representations in the biLM.
对于每一个词$t_k$,一个L层的biLM可以计算出$2*L+1$个表达如下:
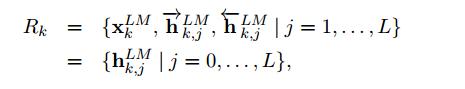
其中$h_{k,0}^{LM}$来表示第一层向量,$h_{k,j}^{LM} = [\overrightarrow{h}_{k,j}^{LM}; {\overleftarrow{h}}_{k,j}^{LM}]$。\
为了包含在下游模型中,ELMo将R中的所有层折叠成一个向量,$ELMO_k = E(R_k; \circleddash_e) $。
在最简单的情况下,ELMo只选择顶层,$E(R_k) = h_{k,L}^{LM}$,和TagLM和CoVe一样。
ELMO本质上就是一个任务导向的、双向语言模型(biLM)内部的隐状态层的组合。通用的表达式如下:

在(1)中,s^task^是softmax-normalized权重,标量参数$\gamma^{task}$允许任务模型缩放整个ELMo向量。其中$\gamma $有助于进行优化。考虑到每个biLM层的激活度分布不同,在某些情况下,在加权前对每个biLM层应用归一化层(Ba et al., 2016)也有所帮助。
$ \gamma $是用来控制ELMO模型生成的向量大小,原文中说该系数对于后续的模型优化过程有好处(在附件中,作者强调了这个参数的重要性,因为biLM的内核表达,与任务需要表达,存在一定的差异性,所以需要这么一个参数去转换。并且,这个参数对于,last-only的情况(就是只取最后一层,ELMO的特殊情况),尤其重要),另一个参数s,原论文只说了softmax-normalized weights,所以我的理解,其实它的作用等同于层间的归一化处理。(引用自)
Using biLMs for supervised NLP tasks
在给定目标NLP任务的预训练biLM和监督体系结构的情况下,利用biLM改进任务模型是一个简单的过程。我们只需运行biLM并记录每个单词的所有层表示。然后,我们让终端任务模型学习这些表示的线性组合,如下所述:
- 首先考虑无biLM的监督模型的最低层。大部分的NLP的模型都会有一层词向量层,而我们要做的无非就是用ELMO与词向量层结合。然后,模型生成一个上下文敏感的表示$h_k$,通常使用双向RNNs、CNNs或前馈网络。
- 为了将ELMo添加到监督模型中,我们首先冻结biLM的权值,然后将ELMo向量$ELMo_k^{task}$与 $x_k$ 连接,并将ELMo增强表示$[ x_k ; ELMo_k^{task}]$c传递到RNN中。
- 发现:在ELMo中添加合适的dropout和某些情况下在loss中添加$\lambda ||w||_2^2$正则化ELMo权重都是有益的。这对ELMo权重施加了一个归纳偏差,使其接近所有biLM层的平均值。
Pre-trained bidirectional language model architecture
本文预训练的biLMs与Jozefowicz等人(2016)和Kim等人 (2015) 的体系结构相似,但加以修改以便支持两个方向的联合训练,并在LSTM层之间添加了剩余连接。在这项工作中,作者重点关注大规模的biLMs,正如Peters等人(2017)强调了使用biLMs比只使用前向LMs和大规模训练更重要。
最终作者用于实验的预训练模型,为了平衡语言模型之间的困惑度以及后期NLP模型的计算复杂度,采用了2层Bi-Big-Lstm,共计4096个单元,输入及输出纬度为512,并且在第一层和第二层之间有残差连接,包括最初的那一层文本向量(用了2048个过滤器, 进行基于字符的卷积计算,详细可查看字符卷积的原论文),整个ELMO会为每一个词提供一个3层的输出,而下游模型学习的就是这3层输出的组合。另外,作者强调了一下,对该模型进行FINE-TUNE训练的话,对具体的NLP任务会有提升的作用。
4. 实验
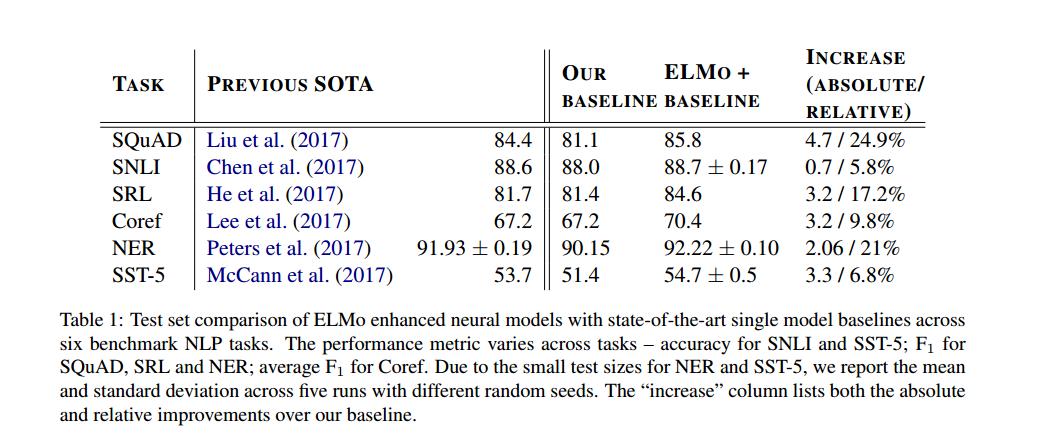
论文的实验部分,具体展示了ELMO在六大nlp任务上的表现(如Tabel 1),证实了该模型的有效性。此处未具体展开,只罗列了SRL。
数据集及评价标准介绍
Semantic Role Labeling(SRL)是对句子的predicate-argument结构进行解析的过程,通常被描述为“回答谁对谁做了什么(Who did what to whom )”。He(2017)等人将SRL作为一个BIO标记问题,并使用了一个8层的前后方向交错的深层biLSTM。
Baseline介绍
结果分析
在下游任务中使用深层上下文表示比仅使用顶层的先前工作提高了性能,无论它们是由biLM或MT编码器生成的,而且ELMo表示提供了最佳的总体性。整体趋势与CoVe相似,但在基线上增幅较小。
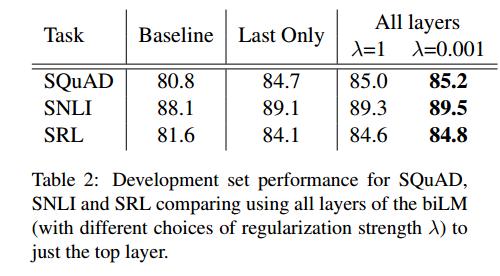
- 探索了在biLMs中捕获的不同类型的上下文信息,并使用了两个内在的评估来表明,语法信息在较低的层中更好地表示,而语义信息在较高的层中捕获,这与MT编码器一致。它还表明,本文中的biLM始终提供比CoVe更丰富的表示。ELMO不同的层,能从不同的纬度表达一个词,作者经过实验发现,低层的输出能更好的从句法语法的层面表达一个词,而高层的输出能更好的从语意的层面表达一个词
ELMo在任务模型(第5.2节)、训练集大小(第5.4节)中的敏感性,并可视化了ELMo在任务中学习到的权重(第5.5节)。
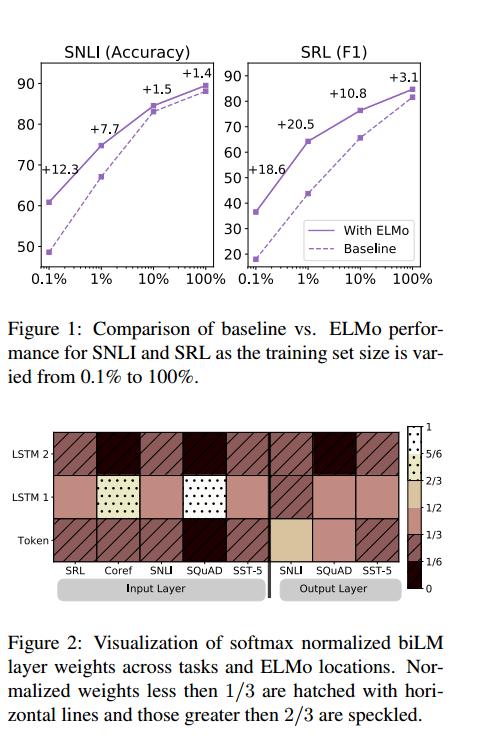
- 加ELMO的位置:是与之前的词向量层一起,在最开始的地方。作者还实验了一把,发现在特定于任务的体系结构中,在biRNN的输出中包含ELMo可以改进某些任务的总体结果。如表3所示,在SNLI和SQuAD的输入层和输出层都包含ELMo,这比仅仅在输入层有所改进,但是对于SRL(以及没有显示的协引用分辨率),当它只包含在输入层时,性能是最高的。一个可能的解释是SNLI和小队架构在biRNN之后都使用了注意层,所以在这一层引入ELMo允许模型直接关注biLM的内部表示。
5. 结论
本论文主要集中在于阐述ELMO结构及其预训练的思想,并且用具体NLP实验证明了使用这一套结构的原理,并证实了其可行性。
你觉得这篇paper创新与贡献是(不一定如作者所说)?为什么?
本文介绍了一种从biLMs学习高质量的深度上下文相关表示的通用方法,并在将ELMo应用于广泛的NLP任务时显示了很大的改进。
通过一些实验也证实了biLM层可以有效地编码关于语境用词的不同类型的语法和语义信息,并且使用所有层可以提高整体任务性能。
有没有进一步深入的价值?为什么?
目前只停留在使用的过程中。
列出该文弱点(或者是你觉得应该是什么问题,他解决的不好,你会如何解决?)
该文对你的启发是?
将ELMO用于Sytactic Parsing中。
列出其中有价值的需要进一步阅读的参考文献
1、BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding