
Semantic Role Labeling for Learner Chinese–the Importance of Syntactic Parsing and L2-L1 Parallel Data

本文阅读目的:了解SRL标注工作及在现有parsing model上的评估与分析,目前仅作为Dependency SRL研究工作的基础知识进行相关了解,此外对于文中所提到的SRL模型并未做进一步了解。
题目与摘要
本文针对什么任务?任务简要介绍下。
本文主要以面向汉语学习者的中介语(interlanguage, L2)的语义分析为研究对象,进行语义角色标注(Semantic Role Labeling, SRL)。
语义角色标注(from reference)
- 自然语言分析技术大致分为三个层面:词法分析、句法分析和语义分析。语义角色标注是实现浅层语义分析的一种方式。在一个句子中,谓词是对主语的陈述或说明,指出“做什么”、“是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为谓元(论元)。语义角色是指谓元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等
- 语义角色标注(SRL)任务是指以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
- Motivation: From Sentences to Propositions(抽取句子的主干意义)
- 详细介绍
本文发现了什么问题?该文大体是怎么解决的?解决得如何?
本文工作首先为一组学习者文本手工标注语义角色,以获得进行自动SRL的黄金标准。并基于这些新标注的数据,在三个现有的SRL系统(the PCFGLA-parser-based, neural-parserbased, neural-syntax-agnostic systems )上进行评估来衡量SRL在学习者汉语文本上的解析性能。 针对评估结果作者提出了两点不太明显的结论:
(1)L1句子训练的系统对L2数据的处理能力较差;
(2)两种parser-based系统在解析L1数据到L2数据的时候性能下降要小得多,这说明了SRL中句法分析对于跨语言的重要性。
针对以上结论,作者提出了一种面向大规模L2-L1平行数据的agreement-based model来探索语义一致性 (coherency ) 信息。同时也证明了这些信息对于提高L2的语篇学习水平是非常有效的。最终结果获得了72.06分的F-score,比最佳基线提高了2.02分。
解释下题目。题目起得如何?能概括内容并吸引人吗?
简要明了:
- Semantic Role Labeling Learner Chinese 指明是面向汉语中介语的语义角色标注工作
- the Importance of Syntactic Parsing and L2-L1 Parallel Data 指明本文中心立意
介绍
学习者语言(中介语)是由第二语言学习者或外语学习者发展起来的一种个人习语,它可能保留了一些学习者母语的某些特征。
这个任务以往是如何解决的?作者沿着哪条路径继续研究的?为什么?
之前关于构建学习者语言的自动句法分析工作相当令人振奋(Nagata
and Sakaguchi, 2016) ,但是对于语义处理是如何执行的仍然是未知的,而将学习者语言(L2)解析为语义表示是对学习者语言进行各种深入分析的基础,例如作文自动评分。因此,在本文中作者以语义角色标注(SRL)为案例任务,以汉语学习者为案例语言,研究中介语的语义分析。
目前存在什么问题?为什么?你觉得可能还存在什么其他问题?为什么?
本文从三个concern展开介绍自己的研究工作:
本文作者提出:在讨论计算系统之前,首先考虑语言能力和语言运用。并提出了以下疑问:
人类能够准确地理解学习者的文本吗?或者更准确地说,以英语为母语的人能 在多大程度上理解语言学习者写的句子的意思?
Can human robustly understand learner texts? Or to be more precise, to what extent, a native speaker can understand the meaning of a sentence written by a language learner?
作者提出的第二个关注点是如何通过计算机程序模拟人类的语义处理能力。
探索大规模的L2-L1并行语料是否有助于增强SRL系统。
该文准备如何解决这个问题?为什么可以这样解决?你觉得该文解决这个问题的方法如何?为什么?你觉得可以如何/或更好的解决这个问题?为什么?
直觉上,以上问题(1)答案是积极的一面。为了验证这一点,作者根据 Chinese PropBank (CPB)的规范(针对L1的),标注了一些L2-L1平行句子的 predicate–argument (谓语-论元)结构。较高的标注一致度表明,这种规范对于L2的语言理解具有很高的鲁棒性。【此工作也是在进行Dependency parsing的标注工作模式】。在语义标注过程中,作者提出:可以重用为L1开发的语义标注规范Chinese PropBank来标注L2句子中的语义角色。
During the course of semantic annotation, we find a non-obvious fact that we can re-use the semantic annotation specification, Chinese PropBank in our case, which is developed for L1. Only modest rules are needed to handle some tricky phenomena. This is quite different from syntactic treebanking for learner sentences, where defining a rich set of new annotation heuristics seems necessary
问题(1.)中关于重用L1标注规范的可行性意味着可以用标准的CPB数据来训练一个SRL系统来处理学习者的文本。为了测试最优SRL算法的鲁棒性,论文在两种SRL框架进行了评估。
Syntax-based Systems
Neural Syntax-agnostic System
结论:两个系统都可以在L1文本实现最优性能,但对L2文本的性能有明显的下降。这就凸显了运用L1句子训练的系统来处理学习者文本的弱点。根据分析,主要原因是Syntax-based系统可以对L2文本中的部分语法片段生成正确的句法分析,这为SRL提供了重要的信息。因此,句法分析有助于构建更通用的SRL模型,以便更好地向新语言传输,增强句法分析可以在一定程度上改进SRL。
由于L2-L1平行句子的语义结构是高度一致的,从而提出设计一个新的基于协议(agreement-based)的模型来探索语义一致性信息(semantic coherency information)。还定义了一个metric用于用于比较predicate–argument 结构和搜索相对较好的自动句法和语义注释,以扩展SRL系统的训练数据。实验结果表明L2-L1平行句子对于增强SRL的有效性,且F-score达到72.06,比neural-parser-based的最佳baseline提高了2.02个百分点。
列出该文贡献(该文自己觉得的)
1、基于CPB规范,构建了L2-L1平行语料的SRL语料库,经验证可以重用为L1开发的语义标注规范CPB来标注L2句子中的语义角色。(Feng et al., 2012)
2、借助L2-L1平行句子的语义结构的高度一致,设计了一个agreement-based模型,F-score达到72.06,高于neural-parser-based的最优结果2.02。
3、 提出利用L2-L1并行语料来增强学习者文本的NLP系统这一观点也是第一次提出。
模型
整体介绍(主要是图)
模型创新点
(仅对要进一步跟进的paper)详细介绍模型,从输入到输出,输入矩阵维度,公式等
L2-L1平行语料库的语义分析
L2-L1平行语料库的构建
通过探索“语言交流”社会网络服务(SNS)(例如,Lang-8,学习者都处于中等或较低水平 ),收集了大量汉语普通话的L2-L1并行文本数据集,最终得到1,108,907个句子对(135,754篇文章)
清洗数据
- 排除冗余内容
- 通过检查Unicode值排除包含外国文字或汉语拼音字母的句子
- 删除过于简单的句子(可能没有什么信息)
- 使用基于规则的分类器来决定是否将句子包含到语料库中
最终得到一个由61种不同母语背景的作者所写的717241个L2句子组成的语料库,其中英语和日语占大多数。对应的L1来自Lang-8网站上母语人士(82.78%)对这些句子的修正(平均每个句子修正1.53次)。
最终数据集
从以上构建的语料库选取600个L2-L1句子对,手工标注predicate-argument结构。
分词:选用最佳分词系统进行初步分词,再针对自动分词结果进行手工修正。
数据集包括四种不同类型的母语背景:
| Mother tongues | sentence pairs |
| ————– | ————– |
| English(ENG) | 150 |
| Japanese(JPN) | 150 |
| Russian (RUS) | 150 |
| Arabic (ARA) | 150 |
标注工作
语义角色标注(SRL)是根据句子中所表达的谓词与成分之间的关系,为句子中的成分或它们的head word 分配语义角色的过程。典型的语义角色可以分为核心论元(core arguments)和附加状语(adjuncts)。核心论元包括Agent、Patient、Source、Goal等,附加状语包括Location、Time、Manner、Cause等。
Inter-annotator Agreement
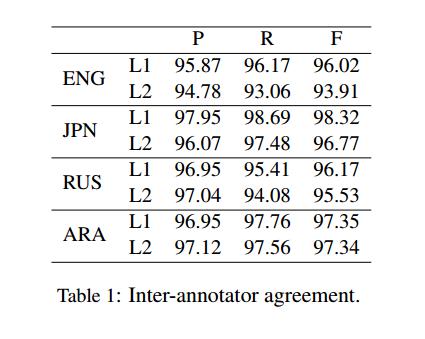
- 评估了两个标注结果的语义标签的精确度(P)、查全率(R)和F1-score (F),结果如表1。
只有适度的规则才能处理一些棘手的现象(Only modest rules are needed to handle some tricky phenomena):
1. 标记的论元应该严格限制在CPB的框架集 中定义的核心角色,尽管L2句子中的argument数量可能比定义的数量多或少。
2. 对于在CPB规范下不能标注为arguments的L2角色,如果它们提供了时间、位置、原因等语义3信息,我们将它们标注为状语修饰语,尽管因为没有虚词,它们可能不是格式良好的状语。
3. 对于L2中由于动词次类划分错误而产生的不必要的角色(参见图3b中的例子),我们将不标记这些角色。
与语言和角色类型相关的注释器间协议(F-scores)
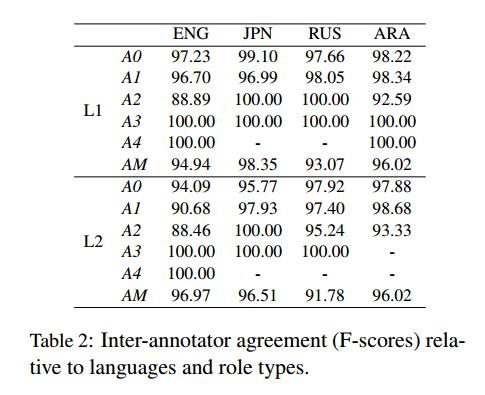
表2详细报告了关于每个论元(AN)和附加状语(AM)的一致度,根据这些一致度结果,高分归因于对论元(AN)的高度一致。A3和A4的标签没有分歧,因为它们在CPB中是稀疏的,通常被用来标记具有很少歧义的特定语义角色。
:smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley: :smiley:
实验(Evaluating Robustness of SRL )
数据集及评价标准介绍
数据集
- CPB
- Chinese Treebank
- CoNLL 2009 shared task中的句子用于参数评估
评价标准
- 由于L2句子的单词与L1句子的单词不一定匹配,因此为了确定比较谓语-论元结构的度量标准论文中使用了一个自动单词对齐器。BerkeleyAligner(Liang et al., 2006)是一种用于获得单词对齐的最先进的工具。
- 比较两个句子的SRL结果的度量方法是基于$<w_p, w_a, r>$元组的召回率(Recall),其中$w_p$是谓语,$w_a$是在$w_p$的论元或附加状语中的一个词,而$r$是对应的语义角色。基于单词对齐,我们将共享元组定义为L2-L1句子对的两个SRL结果之间的相互元组,即谓词和实参单词都是对齐的,它们的角色关系是相同的。因此有两个recall值:
- L2-recall is (# of shared tuples) / (# of tuples of the result in L2)
- L1-recall is (# of shared tuples) / (# of tuples of the result in L1)
Baseline介绍
三个SRL系统上进行实验:
Sytax-based SRL(Gildea and Jurafsky, 2000; Xue, 2008 ):传统的SRL系统,利用句法分析器和繁重的特性工程获取到显式信息(explicit information)来找到语义角色, 使用了两个不同的解析器进行比较:
PCFGLA-parser-based:Berkeley parser,the unlexicalized latent variable PCFG model. (Petrov et al., 2006)
neural-parser-based:a minimal span-based neural parser based on independent scoring of labels and spans. (Stern et al., 2017)
其中neural-parser-based在Penn Treebank上实现了最佳的单模型性能,而在CTB数据上的域内测试性能也优于Berkeley parser。
**(He et al., 2017 )。
Neural Syntax-agnostic System:该模型将SRL作为一个BIO标注问题,并使用堆叠的BiLST(M获取informative embeddings)隐式地捕获局部和非局部信息,是一个端到端的神经SRL模型。因为所有的句法信息(包括POS标签)都被排除在外,所以称这个系统为神经句法无关系统(neural syntax-agnostic system)。
结果分析
Main Results
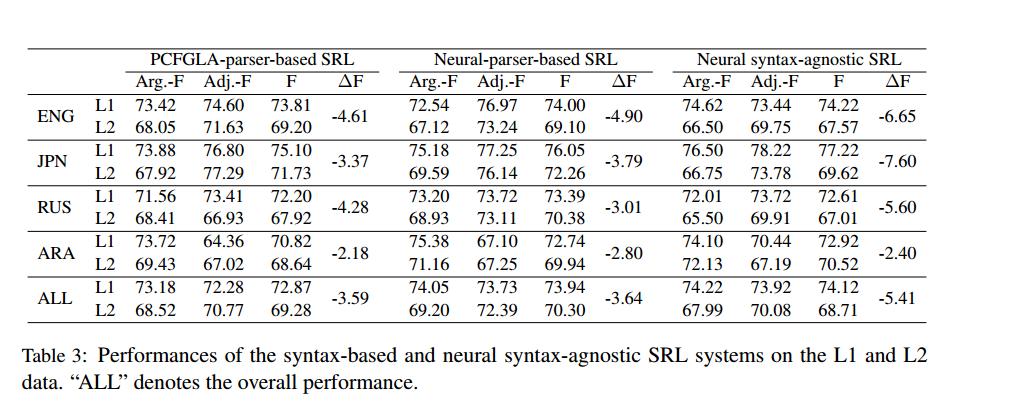
在三个系统中,不同母语的显著性下降都是可以观察到的,这突出了应用L1句子训练的系统处理学习者文本的弱点。对比两种Sytax-based系统与syntax-agnostic系统发现,Sytax-based框架的总体$\Delta F$值(表示从L1到L2 F-score的下降值)要小于syntax-agnostic系统。
neural-parser-based系统在L2数据上取得了最好的整体性能。
Analysis
为了更好地理解整体结果,作者通过解决以下问题进一步深入研究了输出:
- 什么类型的错误会对学习者的文本产生负面影响
- 对于L2数据, 哪种类型的错误在neural syntax-agnostic上更有影响,但是基于语法的错误在一定程度上可以解决。
(1)Breaking down Error Types 分解错误类型

采用 He et al. (2017)等人提出的6个oracle transformations,依次修正各种预测错误(详见表4)。
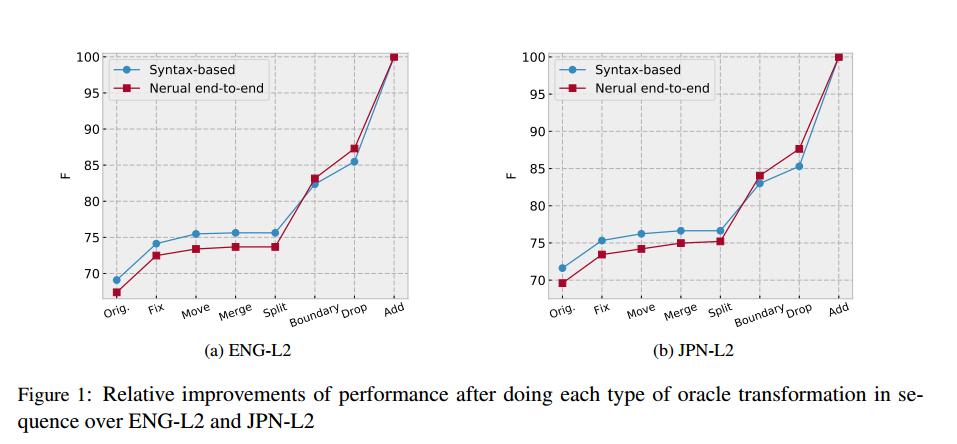
图1分别比较了两个系统在ENG-L2和JPN-L2上的不同错误。在确定了span的边界后,neural syntax-agnostic系统赶上了另一个系统,这说明尽管两个系统都不能很好地处理L2句子的边界检测,但neural syntax-agnostic系统更容易出现这类错误。
排除边界错误(移动、合并、分割spans和固定边界后),对L2上的两个系统进行了详细的标签标识比较,以观察哪个语义角色更容易被错误标识。图2显示了混淆矩阵。
- 对比(a)与(c)、(b)与(d),我们可以看到Sytax-based系统在处理学习者文本时常常过度标注A1。
- 与Sytax-based系统相比,神经Syntax-agnostic系统对L2句子的AM(附加状语)的预测要高出54.24%。

(2)Examples for Validation
在(1)中典型错误类型(边界检测和标签错误)分析的基础上,进一步对输出句子进行了调查。
Boundary Detection
之前的研究工作提出SRL系统性能下降主要发生在识别论元边界,根据本文的实验结果发现,这一问题在L2句子中更加严重,而句法结构有时可以帮助解决这个问题。图3是一些例子。
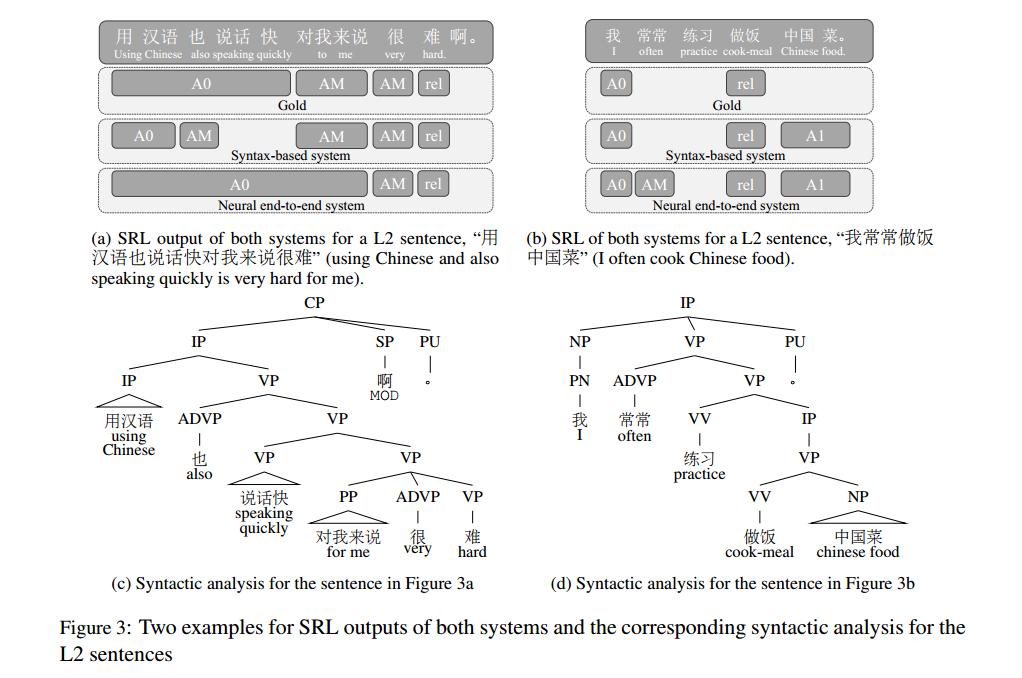
Mistaken Labels
第二个常见的错误类型是错误的标签,尤其是A1。经过对表5的定量分析,显示这些现象主要是由动词次类划分的错误造成的,系统标注的论元多于谓语所允许的。此外,深层的端到端系统也可能错误地将附加状语AM附加到谓语上。

使用L2-L1并行数据增强SRL
探讨了L2-L1并行数据中语义一致性部分的有效价值信息,以提高汉语学习者的学习水平。特别地,引入了一个基于协议的模型来搜索高质量的自动句法和语义角色注释,然后使用这些注释来重新训练两个基于解析器的SRL系统。
Method
为了获得良好的自动句法和语义分析,论文中考虑了学习者句子以及其对应的结构良好的句子的自动生成分析之间的一致性。首先对句子中的词进行词对齐处理,然后通过评价标准中的方法选取得分最高的句子进行自动分析,并将其用于扩展训练数据。
L1和L2的reca都大于阈值p的句子被认为是好句子。基于解析器的SRL系统由两个基本模块组成:句法解析器和语义分类器。
为了增强句法分析器,直接使用语义一致性高的句子对自动生成的句法树来扩展训练数据。
为了改进语义分类器,除了一致性语义分析外,还使用了神经Syntax-agnostic SRL系统生成的L1数据的输出。
Experimental Setup
dataset
| | 1200 |
| —————- | ———————————————————— |
| development data | 每个语言包含50对L2-L1句子对,共200对。
超参数使用development data进行调优。 |
| L2 test data | 包含每种语言剩余的L2句子,共400句 |
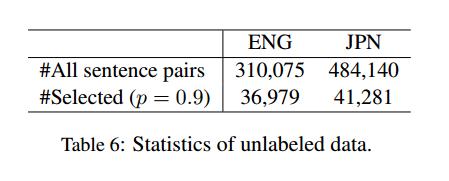
| L1 test data | 包含每种语言剩余的L1句子,共400句 |用于提取再训练标注的句子库包括所有以英语和日语为母语的人的数据及对应的L1, Tabel 6给出了基本统计数据。大约有8-11.9%的句子可以作为high L1/L2 recall句子,这一情况反映了Vazquez(2004)和Shin(2010)提出的论元结构对语言习得至关重要,但对学习者来说也是难以掌握的地方。
Main Results
Table7
- 当使用SRL-consistent句子对PCFGLA句法分析器进行重新训练时,它能够为L2句子及其纠正(L1)句子提供更好的SRL-oriented的句法分析。
- 深层SRL系统生成的L1句的输出对改进线性SRL分类器也有一定的帮助。
- 结论:这种重新训练的模型不仅能更好地分析L1句子,还能更好地分析L2句子。幸运的是,将这两个结果结合起来可以得到进一步的改进。
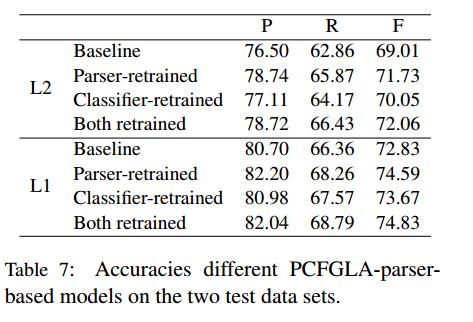
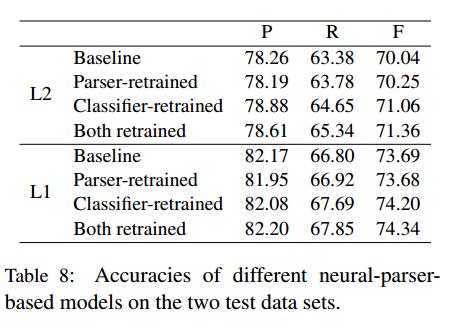
Table 8
- 与PCFGLA模型不同的是,SRL-consistent树对L2数据的改进幅度很小。但对SRL分类器进行再训练要有效得多。
- 这个实验强调了不同框架在解析方面的不同优势。对于标准的域内测试,neural parser的性能更好,但对于其他一些场景,PCFGLA模型更强。
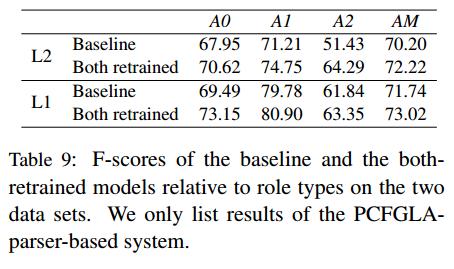
Tabel 9
假设A3和A4两种型号的F-scores都为0时,从图中可以看出,所有的语义角色在性能上都取得了显著的改进。
结论
本文着手于少有的跨语言语义分析的工作,以语义角色标注为案例任务,以汉语学习者为案例语言来探讨这一课题。揭示了三个对深入分析学习者语言非常重要的未知事实:
- the robustness of language comprehension for interlanguage,中介语对语言理解的稳健性
- the weakness of applying L1-sentence trained systems to process learner texts, 运用L1-sentence训练系统处理学习者文本的不足
- the significance of syntactic parsing and L2-L1 parallel data in building more generalizable SRL models that transfer better to L2。句法分析和L2-L1并行数据对构建更通用的、能更好地传递到L2的SRL模型的意义。
你觉得这篇paper创新与贡献是(不一定如作者所说)?为什么?
提出并构建了L2-L1平行语义角色标注语料库,提供了一个用于处理L2数据的SRL-oriented句法分析器和语义分类器。并对一些最先进的系统进行了显著的数值改进。同时这也是第一个证明大规模L2-L1并行数据有效增强学习者文本NLP系统的工作。
有没有进一步深入的价值?为什么?
有,证明了句法在对学习者文本的语义结构中具有重要的研究价值与意义,以及L2-L1平行语料库对于SRL的增强。
列出该文弱点(或者是你觉得应该是什么问题,他解决的不好,你会如何解决?)
该文对你的启发是?
对于下一步进行Dependency Parsing标注工作以及Dependency SRL工作有较大的指导意义。