
Deep Learning with PyTorch:A 60 Minute Blitz
一、PyTorch 是什么
它是一个基于Python的科学计算包,目标用户有两类:
- 为了使用GPU来替代numpy。
- 一个深度学习援救平台:提供最大的灵活性和速度。
开始
张量(Tensors)
张量类似于Numpy的ndarrays,不同之处在于张量可以使用GPU来加快计算。
from __future__ import print_function
import torch
构建一个未初始化的5*3的矩阵:
x = torch.empty(5, 3)
print(x)
构建一个随机初始化的矩阵:
x = torch.rand(5, 3)
print(x)
构建一个以零填充且数据类型为long的矩阵:
x = torch.zeros(5, 3, dtype=torch.long)
print(x)
直接从数据构造张量:
x = torch.tensor([5.5, 3])
print(x)
也可以根据现有张量创建张量。这些方法将重用输入张量的属性,例如dtype,除非用户提供了新的值:
x = x.new_ones(5, 3, dtype=torch.double) #new_* methods 获取大小
print(x)
x = torch.randn_like(x, dtype=torch.float) # 重写dtype
print(x) # 结果具有相同的大小
获取张量大小:
print(x.size())
注意:torch.Size实际上是一个元组,所以它支持所有的元组操作。
操作(Operations)
张量上的操作有多重语法形式,下面我们一加法为例进行讲解。
加法:语法1
print("x: ", x)
y = torch.rand(5, 3)
print(x + y)
加法:语法2
print("x: ", x)
print(torch.add(x, y))
加法:提供输出张量作为参数
result = torch.empty(5, 3)
torch.add(x, y, out=result)
print(result)
加法: in-place
#adds x to y
y.add_(x)
print(y)
注意:任何使张量在原位发生变异的操作都是用, 例如: x.copy(y), x.t_(),都将会改变x。
可以任意使用标准Numpy-like索引:
print(x)
print(x[:, 1])
print(x[1, :])
print(x[2, 4])
调整大小(Resizing):如果您想调整大小/重塑张量,可以使用torch.view
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8)
print(x.size(), y.size(), z.size())
如果有一个单元张量(a one element tensor),请使用.item()将该值作为Python数字来获取
x = torch.rand(1)
print(x)
print(x.item())
这里描述了100+张量操作,包括转置,索引,切片,数学运算,线性代数,随机数等。
NumPy Bridge
把一个torch张量转换为numpy数组或者反过来都是很简单的。
Torch张量和numpy数组将共享潜在的内存,改变其中一个也将改变另一个。
将Torch张量转换成一个NumPy数组 :
>>> a = torch.ones(5)
>>> print(a)
Out: tensor([ 1., 1., 1., 1., 1.])
>>> b = a.numpy()
>>> print(b)
Out: [1. 1. 1. 1. 1.]
numpy数组的值如何在改变?
a.add_(1)
print(a)
print(b)
把NumPy数组转换成Torch张量:
看看改变numpy数组如何自动改变torch张量。
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)
所有在CPU上的张量,除了字符张量,都支持在numpy之间转换。
CUDA 张量
使用 .to 函数可以将张量移动到GPU上。
# let us run this cell only if CUDA is available
# We will use ``torch.device`` objects to move tensors in and out of GPU
if torch.cuda.is_available():
device = torch.device("cuda") # a CUDA device object
y = torch.ones_like(x, device=device)
x = x.to(device)
z = x + y
print(z)
print(z.to("cpu", torch.double))
Out:
tensor([ 0.5921], device=’cuda:0’)
tensor([ 0.5921], dtype=torch.float64)
Autograd: 自动求导(automatic differentiation)
PyTorch中所有神经网络的核心是autograd包。我们首先简单介绍一下这个包,然后训练我们的第一个神经网络。
autograd包为张量上的所有操作提供了自动求导.它是一个运行时定义的框架,这意味着反向传播是根据你的代码如何运行来定义,并且每次迭代可以不同.
接下来我们用一些简单的示例来看这个包。
Tensor
torch.Tensor是包的核心类,如果将其属性requires_grad设置为true,它开始跟踪它上面的所有操作。 当完成计算时可以调用.backward()并自动计算所有的梯度。该张量的梯度被计算放入搭配到.grad属性中。
阻止跟踪历史的张量,可以通过调用.detch()将其从计算历史记录中分离出来,并防止跟踪将来的计算。
为了防止跟踪历史记录(和使用内存),您还可以在 with torch.no_grad()包装代码块。这在评估模型时特别有用,因为该模型可能具有requires_grad = True的可训练参数,但我们不需要梯度。
对自动求导的实现还有一个非常重要的类,即函数(Function)
张量(Tensor)和函数(Function)是相互联系的,并形成一个非循环图来构建一个完整的计算过程.每个变量有一个.grad_fn属性,它指向创建该变量的一个Function(用户自己创建的变量除外,它的grad_fn属性为None)。
如果你想计算导数,可以在一个张量上调用.backward().如果一个Tensor是一个标量(它只有一个元素值),你不必给backward()指定任何的参数,但是该Variable有多个值,你需要指定一个和该张量相同形状的的gradient参数(查看API发现实际为gradients参数)。
import torch
# 创建一个张量,饼设置reuqires_grad=True来跟踪计算过程
x = torch.ones(2, 2, reuqires_grad=True)
print(x)
Out:
tensor([[ 1., 1.],
[ 1., 1.]])
在张量上执行操作:
y = x + 2
print(y)
Out:
tensor([[ 3., 3.],
[ 3., 3.]])
因为y是通过一个操作创建的,所以它有grad_fn,而x是由用户创建,所以它的grad_fn为None.
print(y.grad_fn)
Out: <AddBackward0 object at 0x0000020D2A5CC048>
在张量y上执行更多操作:
z = y * y * 3
out = z.mean()
print("z : ", z, ", out: ", out)
Out: z : tensor([[ 27., 27.],
[ 27., 27.]]) , out: tensor(27.)
.requires_grad_(…)按位(in-place)更改现有张量的requires_grad标志。如果没有给出,输入标志默认为True。
a = torch.randn(2, 2)
a = ((a * 3) / (a - 0))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
梯度
现在我们来执行反向传播,因为out包含一个标量,out.backward()相当于执行out.backward(torch.tensor(1)):
out.backward()
# 输出out对x的梯度d(out)/d(x):
print("x.grad: ", x.grad)
输出:
你应该得到一个值全为4.5的矩阵,我们把out称为张量O。则
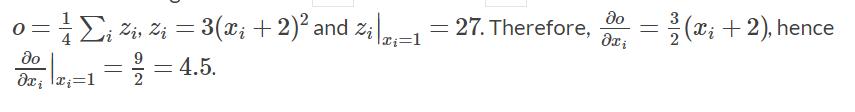
我们还可以用自动求导做更多有趣的事:
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
输出:
gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(gradients)
print(x.grad)

还可以通过使用torch.no_grad()包装代码块来停止autograd跟踪在张量上的历史记录,其中require_grad = True:
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2 ).requires_grad)
输出:
Documentation of autograd and Function is at http://pytorch.org/docs/autograd
神经网络(Neural Networks)
可以使用torch.nn包来构建神经网络。
我们已知道autograd包,nn包依赖autograd包来定义模型并求导.一个nn.Module包含各个层和一个faward(input)方法,该方法返回output。
例如,我们来看一下下面这个分类数字图像的网络。
convnet
这是一个简单的前溃神经网络,它接受一个输入,然后一层接着一层的输入,直到最后得到结果。
神经网络的典型训练过程如下:
- 定义神经网络模型。它有一些可学习的参数(或者权重);
- 在输入数据集上迭代
- 通过神经网络处理输入,主要体现在网络的前向传播;
- 计算损失(输出结果和正确值的差距大小)
- 将梯度反向传播回网络的参数,反向传播求梯度。
- 根据梯度值更新网络的参数,主要使用如下简单的更新原则: weight = weight - learning_rate * gradient
定义网络
Let’s define this network:
import torch
import torch.nn as nn
import torch.nn.functional as F
Class Net(nn.Module):
def __init__(self):
# super就是在子类中调用父类方法时用的。
super(Net, self).__init__() # 对继承自父类的属性进行初始化。而且是用父类的初始化方法来初始化继承的属性。也就是说,子类继承了父类的所有属性和方法,父类属性自然会用父类方法来进行初始化。当然,如果初始化的逻辑与父类的不同,不使用父类的方法,自己重新初始化也是可以的。
# 1 input image channel, 6 output channels, 5*5 square convution
# kernel
self.comv1 = nn.Conv2d(1, 6, 5)
self.comv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x),(2, 2))
# if the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x), 2)
x = view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
输出: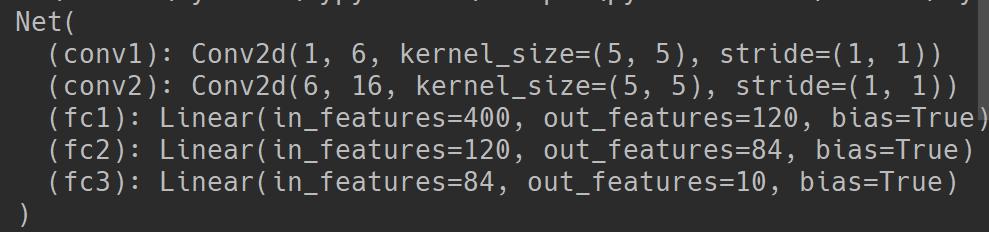
learn more about the network:
在pytorch中只需要定义forward函数即可,backward函数会在使用autograd时自动创建(其中梯度是计算过的)。可以在forward函数中使用Tensor的任何操作。
net.aprameters()会返回模型中可学习的参数。
params = list(net.parameters())
print('可学习参数的个数:', len(params))
#print("可学习的参数:", params)
print(params[0].size()) # conv1's的权值
for param in params:
print(param.size())
以上代码段实现将该神经网络的可学习参数都放到params中,并且输出了第一层conv的参数大小.
输出: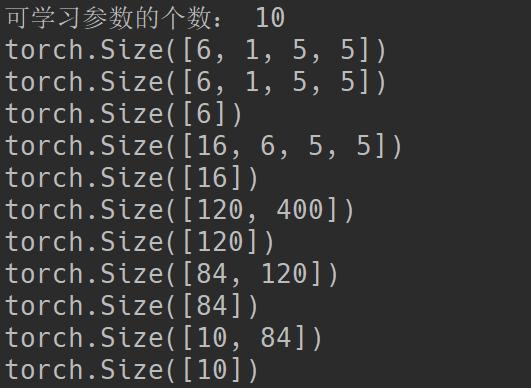
注意:我们来尝试一个3232的随机输入,这个网络(LeNet)期望的输入大小是3232。如果使用的是MINIST数据集来训练这个网络,请把数据集中图片大小调整到32*32。
input = torch.randn(1,1,32,32)
print("input: ", input)
out = net(input)
print("out: ", out)
输出:
把所有参数的梯度缓存区清零,然后进行随机梯度的的反向传播。
net.zero_grad()
out.backward(torch.randn(1, 10))
Note:
- torch.nn只支持小批量输入(mini-batches)。整个torch.nn包仅支持作为最小样本量的输入,而不支持单个样本。
- 例如,nn.Conv2d只接受一个四维张量(nSamples nChannels Height Width),即样本数通道数高度宽度。
- 如果你有单个样本,只需使用input.unsqueeze(0)来添加一个虚假的批量维度.
在继续之前,我们回顾一下到目前为止见过的所有类。
回顾:
- torch.Tensor - 一个支持autograd等操作(比如banckward())的多维数组,也支持梯度w、r、t等张量。
- nn.Module - 神经网络模块。封装参数的便捷方式,移动到GPU运行,导出,加载等。
- nn.Parameters - 一种张量,当作为属性赋值给一个模块(Module)时,能被自动注册为一个参数。
- autograd.Function - 实现一个自动求导操作的前向和反向定义,每个张量操作至少创建一个函数节点,该节点连接到创建Tensor并对其历史进行编码的函数。
以上内容:
- 定义一个神经网络
- 处理输入和调用backward
剩下的内容:
- 计算损失值
- 更新神经网络的权值
损失函数(Loss Function)
一个损失函数接受一对(output, target)作为输入(output为网络的输出,target为实际值),,计算一个值来评估网络的输出和目标值(实际值)相差多少。
在nn包中有几种不同的损失函数。一个简单的损失函数是:nn.MSELoss,它计算的是网络的输出和目标值之间的均方误差。
例如:
output = net(input)
target = torch.arrange(1, 11) # 例如,虚拟目标
target = target.view(1, -1)# 使其与输出(output)形状相同
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
输出:
现在,如果反向跟踪loss,用它的属性.grad_fn,你会的到下面这样的一个计算图:

所以, 当调用loss.backward(),整个图与w、r、t的损失不同,图中所有变量(其requres_grad=True)将拥有.grad变量来累计他们的梯度.
为了说明,我们反向跟踪几步:
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
输出:

反向传播(Backprop)
为了反向传播误差,我们所需做的是调用loss.backward().你需要清除已存在的梯度,否则梯度将被累加到已存在的梯度。
现在,我们将调用loss.backward(),并查看conv1层的偏置项在反向传播前后的梯度。
net.zero_grad()# zeroes the gradient buffers of all parameters
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
输出:

现在我们也知道了如何使用损失函数。
神经网络包包含各种深度神经网络的构建模块和损失函数。完整的文档列表在这里。
接下来是更新权重。
更新权重
最简单的更新权重的方法是:随机梯度下降(SGD)。
weight = weight - learning_rate * gradient
可以通过以下代码实现梯度更新:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
当使用神经网络时,有几种不同的权重更新方法,例如有SGD,Nesterov-SGD,Adam,RMSProp等。为了能够更好地使用这些方法,Pytorch提供了一个小工具包:torch.optim来实现上述所说的更新方法。使用起来也很简单,代码如下:
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
训练分类器(Training a classifier)
What about Data?
一般来说,在处理图像、文本、音频或者视频数据时可以使用标准的python包把数据加载成一个numpy数组, 然后再把这个数组转换成一个 torch.*Tensor。
- 对于图像来说,可以使用Pillow、OpenCV等包。
- 对于音频来说,可以使用scipy和librosa包。
- 对于文本来说,无论是原始的Python还是基于Cython的加载,或者NLTK和SpaCy都是有用的
特别是对于视觉,我们已经创建了一个名为torchvision的软件包,它具有常用数据集的数据加载器,如Imagenet,CIFAR10,MNIST等,以及图像数据转换器,即torchvision.datasets 和 torch.utils.data.DataLoader。
这提供了巨大的便利并避免了编写样板代码。
本例中我们将使用CIFAR-10数据集。它有以下几类: ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。在CIFAR-10数据集中的数据大小是33232,例如尺寸为32x32像素的3通道彩色图像。

训练一个图像分类器
- 使用torchvision加载并归一化(normalizing)CIFAR10训练和测试数据集。
- 定义一个卷积神经网络
- 定义一个损失函数
- 在训练集上训练网络
- 在测试集上测试数据
- 加载和归一化CIFAR10
torchvison能够很简单的加载CIFAR10。
import torch
import torchvision
import torchvision.transforms as transforms
torchvision数集的输出是范围为[0, 1]的PILImage图像。我们将其转换为归一化范围[-1, 1]的张量。
transform = transform.Compose([transform])